class: title, smokescreen, shelf, no-footer # <small>情報技術応用特論 第06回<br>OS(3): ハードウエアの制御</small> <div class=footnote> <small><small> Copyright (C) Ken'ichi Fukamachi <fukachan@fml.org>, 2021-2025. CC BY-NC-SA 4.0 </small></small> </div> --- class: title, smokescreen, shelf, no-footer # <small>競合状態と排他制御</small> <div class=footnote> <small><small> </small></small> </div> --- class: img-right,compact # <small>競合状態とは?</small> <div class=footnote> <small><small> (脚注1) N+1番目に入れる客は? -> (スーパーならFIFOでいいのだろうけれど) OSの場合一般には並んだ順とは限りません。 一時休止しているプロセスを起こすところが複雑 (脚注2) セマフォの詳細は省略;基本情報より難しい試験には出ます e.g. P操作,V操作 </small></small> </div>   <small> - 複数のプロセスがリソース(資源)を取り合う状態 - スーパーの入場人数制限<small>(競合状態の好例,右図)</small> - **最大N人**しか入れません。 入口に**N個のカゴ**があり、 カゴがないときは入れません - N+1人め以降の客は入り口で待ちます - 客が一人でれば一人はいれるようになるので、 待っている客に「入れるようになった」と知らせます - これをモデル化したものが**セマフォ(semaphore)**(ダイクストラ,1965) </small> --- class: compact # <small>一つのリソースを排他制御したい(例: 在庫処理)</small> <div class=footnote> <small><small> </small></small> </div> <small> - 実際にプログラムを書こうとすると**排他制御**が必要になります - 「一つのリソースを取り合う」状態をなんとかするということです - ショッピングサイトの在庫管理が良い例です - 多数のユーザが同時にカートを操作し、 ほぼ同時に購入ボタンをクリックする可能性があります - カートにいれた注文の「確定」とは、 以下の擬似コード(関数「確定」)のように在庫(変数)の値を減らす処理です。 この関数よびだしが**同時に複数おこわれた**時も正しく動くか?が論点です ``` 関数 確定 (商品) { 商品の在庫を -1 する // 在庫 -1 に成功できれば、このお客さんの商品を確保できている // このお客さんの購入品としてデータベースをアップデートなりする... } ``` </small> --- class: compact # <small>間違ったコード: 在庫を -1 するとは?</small> <div class=footnote> <small><small> (脚注) この例の「操作してますフラグ」は(複数のプロセスにまたがる)グローバル変数のイメージで読んでください </small></small> </div> <small><small> - 素直に考えると次のような擬似コードを書きそうですが、これは間違いです ``` if (操作してますフラグ == 0) { // 誰も操作してないなら 操作してますフラグ = 1 // 自分が操作します! 商品の在庫数を取得 商品の在庫を -1 する 操作してますフラグ = 0 // 操作終わりました! } ``` - なぜなら、どこでコンテキスト切り替えするか分からない。 プログラムの途中で中断/再開しうるから  </small></small> --- class: compact # <small>間違ったコード: こう動く可能性があります</small> <div class=footnote> <small><small> (脚注) 何が悪いのでしょうか?各自、少し考えてみてください。 そして次頁の正解と比べてみてください </small></small> </div> <small> ``` A if (操作してますフラグ == 0) { // プロセスAは操作してOKと思っている B if (操作してますフラグ == 0) { // プロセスBも操作してOKと思っている B 操作してますフラグ = 1 // 自分Bが操作します! B Bが在庫数を取得 // たとえば在庫数 = 100 A 操作してますフラグ = 1 // 自分Aが操作します! A Aが在庫数を取得 // Aにも在庫数 = 100 と見えてしまう A 商品の在庫を -1 する // Aが在庫数を 99 に設定 B 商品の在庫を -1 する // Bも在庫数を 99 に設定 A 操作してますフラグ = 0 // 操作終わりました! B 操作してますフラグ = 0 // 操作終わりました! ``` - プロセスAとBが同時に注文しているとすると、 以下のように、 最終的に在庫数が-2(して在庫数98)にならないといけないのに-1(在庫数99)にしかならないことがありえます - どこでプロセスが切り替わるかわからない(前頁を参照)ため、 <br> フラグのチェックと更新タイミングが絶妙に入り乱れた結果、 間違いになっています </small> --- class: compact # <small>正しい動作: これを防ぐには?</small> <div class=footnote> <small><small> </small></small> </div> <small> ``` A* if (操作してますフラグ == 0) { // プロセスAは操作してOKと思っている A* 操作してますフラグ = 1 // 自分Aが操作します! B if (操作してますフラグ == 0) { // Aが操作中Bは操作できない、のちほど再挑戦 A Aが在庫数を取得 // 在庫数 = 100 を取得 A 商品の在庫を -1 する // 在庫数を 99 に設定 A 操作してますフラグ = 0 // Aは操作終わりました! B* if (操作してますフラグ == 0) { // プロセスBが再挑戦、操作できるようになった B* 操作してますフラグ = 1 // 自分Bが操作します! B Bが在庫数を取得 // 在庫数 = 99 B 商品の在庫を -1 する // 在庫数を 98 に設定 B 操作してますフラグ = 0 // Bは操作終わりました! ``` <small> - (a)「条件:だれも操作してない?」の確認と (b)「自分が操作します(フラグを1に設定)」 <br> (擬似コードで * がついている2行)を中断されることなく実行できる保証があればOK - CPUは「同時に二つの動作(条件文と何らかの値の操作)をする」機械語を提供します。 <br> これを使った**排他制御**の機能をカーネルが提供しているので「これを利用する」が正解です </small> </small> --- class: title, smokescreen, shelf, no-footer # <small>排他制御のコード例</small> <div class=footnote> <small><small> (脚注) 本節はカーネル内の実装の話です、ユーザランドのロックの使い方が別途ありますが省略 </small></small> </div> --- class: compact # <small>ロック</small> <small> - 大昔はgiant lock (ジャイアントロック)、現代ではmutex(ミューテックス)を使います - ジャイアントロックの典型は「割り込みを禁止」する実装です - 多重割り込み(割り込み優先度)の応用です - 割り込み優先度を変更し「他の割りこみが出来ない」ようにするのが基本原理です - メリット:**シンプルな実装で分かりやすい**こと - デメリット: 各種**割り込みができない=待ち時間などを有効に使えない**ため、 OS全体の性能に影響をおよぼします。 とくにハードウエアの性能があがるとCPUが遊んでいる時間が増えてしまいます - mutexを使い粒度をあげます - ロックしたい対象ごとのロック変数に対して操作します -> 粒度があがります - できるだけ細かい処理単位で書くことが大事で、 「ある処理を使うフラグをoff/onする」だけのコードを書くことが原則です (実例は後述の条件変数のところで) </small> --- class: compact # <small>擬似コード「ジャイアントロック」(例:HDDへの読み書き)</small> <div class=footnote> <small><small> (脚注1) 非効率? = HDDの読み書きは待ち時間も長いので、その間は他の仕事もできるのに... (脚注2) 長時間処理の例として分かりやすそうなのでHDDを例にしていますが、 実際のTSSならHDDの割り込み優先度を最高に設定などしません。 時計は最高優先度にするでしょうし、 HDDよりもキーボードなど「人間が操作するもので短時間処理のもの」の優先度を高くします </small></small> </div> <small> ``` 関数 HDDへの読み書き (HDD) { // もっとも大味なジャイアントロック版のイメージ 割り込み優先度をあげる // 他の割り込みをうけつけない HDDを読み書きする // HDDの読み書きだけが(排他的に)実行され続ける 割り込み優先度を下げる // 他の割り込みの受け付けを再開 } ``` - ジャイアントロックでは**割り込まれません** - この例ではHDDの読み書きだけを実行しつづけます - 下手をすると数十秒この処理だけを実行しているでしょう - その間、短時間の処理(例:時計をすすめる、キーボードの入力)も受け付けません - 非効率だし、レスポンスが非常に悪い挙動になります </small> --- class: compact # <small>擬似コード「ミューテックス」(例:HDDへの読み書き)</small> <div class=footnote> <small><small> (脚注) イメージ優先で、このあたりは端折っています。 カーネル内の話なので、 この文脈で競合しているコードは、 各プロセスのカーネルモードで動作している部分とか、 LWP(LightWeight Process / カーネルスレッド)。 コードを読まないと分からないのでは... </small></small> </div> <small> ``` 関数 HDDへの読み書き (HDD) { // mutex(を使うけれど単純化された大味)版のイメージ mutexの処理(「HDDを使ってます変数」だけをロック,他の仕事も平行処理が可能) HDDを読み書き mutexのロックを開放 } ``` - 「HDDを使ってます」変数をロックして、「HDDを読み書き」を排他的に処理します - HDDの読み書きと(擬似)並行で他の処理が実行できます - 何が平行実行されるか?はスケジューラ次第ですけど </small> --- class: compact # <small>もう少しモダンな書き方(テクニック)</small> <div class=footnote> <small><small> (脚注1) 粒度 = granuality (脚注2) giant lockのような「他の処理をうけつけない」部分を減らさないとイケません。 そうしないと、 プリエンプションされてコンテキスト切り替えしても意味が無い。 たとえば、切り替えてもデバイスの処理が終わるまで待つ(=休眠するしかない)状態になります (脚注3) 解決策にはコンパイラがサポートする案もあります (脚注4) CV + mutexは、いわゆる鉄板パターンで、開発者がミスをしないようにしてくれます。 定番の細かい手順のいくつかをまとめて書きやすくしたものと考えてよいでしょう </small></small> </div> <small> - OS全体の利用効率や反応速度を上げるには、競合状態をさばく<b>粒度</b>を上げる必要があります - いろいろ細かいことを考えていけば、どんどん粒度があがりますが、 - 緻密なコードの書き方が要求されるようになり、 ミスをさそいがちです - 自力で書くのではなくOSの提供する機能を使うべきです - 次頁は代表例の**条件変数(CV: condition variable)**です - **mutexと条件変数をコンビで使います** </small> --- class: compact # <small>もう少しモダンなコード例:Mutex + CV(条件変数)</small> <div class=footnote> <small><small> (脚注1) 詳細は分からなくてもOK (脚注2) <b>3行目で休眠</b>するところがポイント! <b>cv_wait()はmutexのロックをはずしてから休眠し、復帰する際にmutexを再度ロック</b>します。 休眠中おなじmutexを使う他の処理は実行可 (脚注3) フラグの操作だけをmutexでロック </small></small> </div> <small> ``` 1 mutexでロックをかける 2 while (リソースを使っていますフラグ == 1) { // (mutexロック下で)使用中か?を確認 3 cv_wait(条件変数cv, mutex変数) // 条件変数cvで待つ(待つ間は休眠) 4 } // 注: whileを抜ける時はリソースが使えるようになった時, そしてmutexを再ロック済 5 リソースを使っていますフラグ = 1 // (mutexロック下で)フラグ=1 6 mutexのロックを外す 7 リソースを使う // デバイスドライバの処理本体を書くところ 8 mutexでロックをかける 9 リソースを使っていますフラグ = 0 // (mutexロック下で)フラグ=0 10 条件変数cvで待っているプロセスを起こす // 次に処理できるプロセスはスケジューラしだい 11 mutexのロックを外す ``` <small> - デバイスドライバ(後述)では上記のように書きます。 「リソース」はHDDやキーボードなど各デバイスのこと </small> </small> --- name: pause class: compact,col-2 # <small>(アーカイブ動画で見ている人も)一時停止して休憩</small> <div class=footnote> <small><small> 「30分ごとに雑談(休憩)をしろ」というのが指導教官の教え <br> 正確には「アメリカでは30分ごとにジョークを言わないといけない」だけれど、そんな洒落乙なこと無理:-) </small></small> </div>   --- name: computer-basic class: title, smokescreen, shelf, no-footer # <small>デバイスドライバ</small> <div class=footnote> <small><small> (脚注) 前節「競合状態」の続き(「競合状態」で使うテクニックの説明後、やっとデバドラの話ができます) </small></small> </div> --- class: img-right,compact # <small>例: 時計の動作</small> <div class=footnote> <small><small> (脚注1) いろいろはしょってます (脚注2) コンピュータの時計は内部で「起動時の時刻 + 1/100 * tick」で推定しています。 当然すこしずつ狂うので、 Network Time Protocolで微修正をかけつつtickカウントをとっています (脚注3) 3.ではその他の処理をしてもok。 UNIX第6版では、 プロセス優先度の再計算や、 Nミリ秒後に実行予約された処理がないか?の確認などをしています (脚注4) カーネルが他の処理を実行中にクロックからの割り込みをうけることもありえます。 その場合カーネルが一時中断->時計の処理->元の処理へ復帰 </small></small> </div>  <small><small> 1. クロックを刻んでいる回路からハードウエア割り込み (例: 1/100秒に一回) 2. 実行中のユーザプロセスはプリエンプトされ一時中断、カーネルへ移行 3. 時計のデバドラを実行 - カウント(tick変数)を +1 する 4. ユーザプロセスへ復帰 </small></small> --- class: compact,col-2 # <small>CPUとデバイスの接続形態の代表例(0)</small> <div class=footnote> <small><small> (脚注) 詳細は次頁以降 </small></small> </div>  <small><small> <br> memory mapped </small></small>  <small><small> <br> IO mapped </small></small> --- class: img-right,compact # <small>CPUとデバイスの接続形態の代表例(1): memory mapped</small>  <small> - メモリ上にデバイスアクセス用の場所 - 例:キーボードは0x220 - ポインタ操作でデバイスが制御できるため、 デバイスだけ特別あつかいをしない統一感のあるコードの書き方ができて綺麗 - 機種例 - DEC PDP-11 (UNIXのターゲットマシン) - 最近のCPUほぼ全部 </small> --- class: img-right,compact # <small>CPUとデバイスの接続形態の代表例(2): IO mapped</small> <div class=footnote> <small><small> (脚注1) 当時のIntelの設計思想としては 「PCはメモリが小さいためmemory-mappedでは<b>もったいない</b>ためらしい」 という噂あり <br> (脚注2) 互換性のため、 現代のIntelは多分memory mappedとIO mapped両方とも使っていると思う。 もう中身グチャグチャ </small></small> </div>  <small> - IO mappedもしくは port mapped - メモリは全てプログラム用、デバイスは別枠 - 実装例:Intel CPU - IntelならIOポートというメモリ空間とは別にある回路を経由してデバイスへアクセス </small> --- class: img-right,compact # <small>HDDへの読み書きの全体像(半分は復習)</small> <div class=footnote> <small><small> (脚注) いろいろはしょってます </small></small> </div>  <small> 1. エディタでa.cを読みたい(と命令) 2. **システムコール**をかける(カーネルモードへ移行、エディタは一時中断) 3. HDDの**デバイスドライバ**(以下デバドラ) 4. デバドラからHDDへ命令を送り、処理(READ)が終わるまでデバドラは休止 5. HDDが依頼された処理を終えると**ハードウエア割り込み**をかけてカーネルに合図 6. デバドラに戻り、 kernelは読みこんだa.cの中身をエディタに返す準備をする 7. システムコールから復帰(ユーザモードへ戻り、エディタプロセス再開) 8. エディタでa.cが見えるようになる </small> --- class: compact # <small>HDDデバイスドライバの擬似コード例(前頁の4.部分)</small> <small><small> - デバドラの詳細はハードウエアごとに大きく異なります。 これはDEC PDP-11のRK05というHDDの例でmemory mappedです。 コマンドを書き込んだ瞬間に動作が始まります ``` ポインタ *p; // 2バイト幅の変数へのポインタなので、p--すると2バイト減少することに注意 ポインタpをHDDを制御できるアドレス(65280〜65291番地間)の一番上(65290)に合わせる *p-- = HDD上に書き込む場所の指定(セクタの番号) *p-- = メモリ上のバッファのアドレス *p-- = 読み書きするバイト数 *p = コマンド // memory mappedの例: メモリ上の配置は以下のとおりで、アドレスは十進数表記に変更済 65290 HDD上の場所の指定(セクタの番号) 65288 メモリ上のバッファのアドレス(読み書きする場所、読み書きの方向はコマンド依存) 65286 読み書きするバイト数 65284 コマンド (読み/書きの指定) 65282 デバイス側でエラーの理由を書き込む場所, READ ONLY 65280 HDDのステータス(Drive Status Register, READ ONLY) ``` </small></small> --- class: title, smokescreen, shelf, no-footer # <small>デバイス<br>〜HDD,SSD,磁気テープ〜</small> <div class=footnote> <small><small> (脚注) せっかく物理な話に近づいたので、このまま物理デバイスを概観してみましょう </small></small> </div> --- class: col-2,compact # <small>デバイス: HDD, SSD</small> <div class=footnote> <small><small> (脚注) いまどきの(身の回りにある)PCが使うストレージ端子の規格はSATAかM.2くらいでしょう </small></small> </div>  <small><small> 2.5インチのSATA HDD(左)と、 M.2 SSD(右側の銀色ヒートシンク下の板,よく見えないけど;-) </small></small>  </small></small> 2.5インチのSSD(端子はSATA)、 見栄えは写真(左)のHDDと変わらない (-> ノートPCのHDDをSSDに入れ替えて高速化できる) </small></small> --- class: col-2,compact # <small>デバイスの物理的な話: HDD</small> <div class=footnote> <small><small> (脚注) レコードと一緒ですよ!って説明が通じない世代ですね... orz </small></small> </div> <small> - 小さな磁石(N極とS極)で0と1を表現する媒体 - 磁石の層が金属盤の上に塗られています - 金属板は常に回転しています - 回転速度(分速)は4200〜15,000rpm - 読み書きしたい場所にアームを近づけ、アームの先で磁場を使って読み書きします <br> (アームを直径方向に移動させ、読み書きしたいセクタが回転してくるのを待ちます) - YoutubeなどにHDDを分解して動作させている動画があるので、 それらを見た方がわかりやすいでしょう(-> 右の動画) </small>  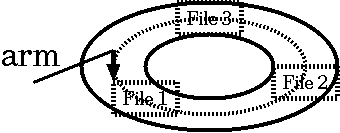  <!-- <iframe width="240" height="160" src="https://www.youtube.com/embed/J6VQGveQXNo?rel=0" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe> --> <iframe width="240" height="160" src="https://www.youtube.com/embed/oGygwiprEbA?rel=0" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe> --- class: col-2,compact # <small>デバイスの物理的な話: HDDのメリット、デメリット</small> <div class=footnote> <small><small> (脚注1) 最近はセンサーで墜落を関知した場合アームを固定して衝撃に備えてます (脚注2) 2021年末、Seagateが20TBのHDDを発売 <br> (脚注3) アームは円盤上20nm ... もしHDDが飛行機サイズとしたら翼は地上数mmでしかない。 この精度で15000回転/分です...すごい </small></small> </div> <small> - 枯れた技術 - コストパフォーマンスがよい - 保存性能も予想以上に高い </small>  --- class: col-2,compact # <small>デバイスの物理的な話: HDDのデメリット</small> <div class=footnote> <small><small> (脚注1) 磁気媒体も原子1個サイズにはなりません。 かなりの数(数十万個?)の原子数で一塊の磁気的記録装置となっています。 原理的には12個で1ビットの実験に成功しているらしい (脚注2) 密閉型で、ヘリウムの中で回るHDDもありますね </small></small> </div> <small> - ある程度の円盤の大きさは必要です(脚注1) - 円盤を回しアームを動かすため <small> - 回転させる電力が必要 - 速度にも限界があります - 衝撃に弱い - ランダムアクセスは不得意 </small> - 開放系 <small> - HDDは密閉されておらず、円盤は空気の粘性からくる圧力を利用して浮いています - 周囲の騒音(->動画)や空気の汚れの影響を受けます </small> </small> <iframe width="480" height="320" src="https://www.youtube.com/embed/tDacjrSCeq4?rel=0" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe> --- class: img-right,compact # <small>デバイスの物理的な話: SSD(1)</small> <div class=footnote> <small><small> (参考) <A HREF="https://www.slideshare.net/InsightTechnology/dbts-osaka-2014-b11-hardware-hironobuasano"> いまさら聞けないSSDの基本 </A> by (今はInsight Technology)の浅野さん (脚注) 量子力学効果のため、そろそろ微細化も限界で... </small></small> </div> 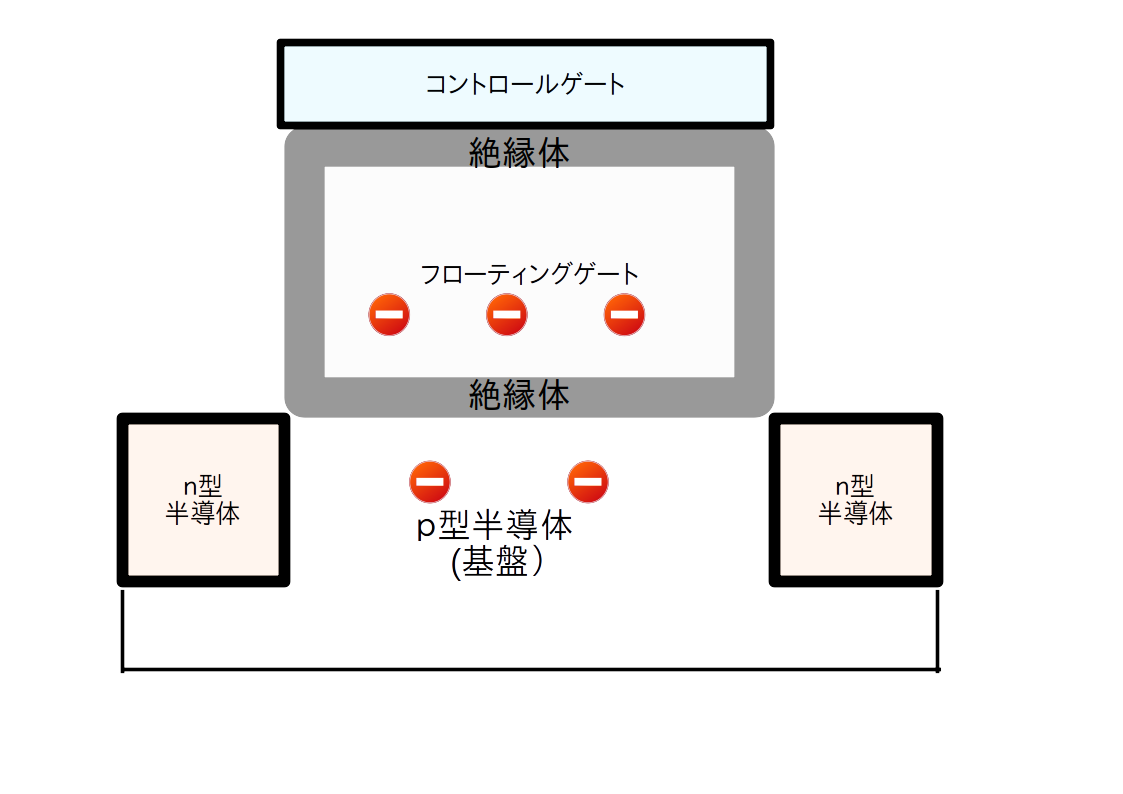 <small> - LSI - 絶縁体の箱の中に電荷がある/なしで1/0を表現 - **SLC**は1/0(1bit) - 多値化 - **MLC**(2bits) - **TLC**(3bits) - 箱内の電子量を細かく判定 - 書き込みや消去は**電圧をかけて強引に絶縁体を越えて電荷を移動**させます <br> (これがSSDを痛める原因の一つです) </small> --- class: img-right,compact # <small>デバイスの物理的な話: SSD(2)</small> <div class=footnote> <small><small> (参考) <A HREF="https://www.slideshare.net/InsightTechnology/dbts-osaka-2014-b11-hardware-hironobuasano"> いまさら聞けないSSDの基本 </A> by (今はInsight Technology)の浅野さん (脚注) 量子力学効果のため、そろそろ微細化も限界で... </small></small> </div>  <small> - 大きく分けて二つの型がります - 右図は**フローティングゲート**型。 箱内の電子量により基盤側に流れる電流が変化するので、 そこから値(1-3bits)を判断します - もうひとつ**チャージトラップ**型というのがあり、TLCは両タイプの製品があります - **微細化は限界** - **3D**(縦方向の積層数)で勝負中 - ようは高層マンション化ですね </small> --- class: compact # <small>デバイスの物理的な話: SSDのメリット</small> <div class=footnote> <small><small> (脚注1) ランダムアクセス ... LSIのセクタ番号を指定するだけなので、どの場所でも同一速度ですが、 HDDは円盤の回転とアームの移動が必要なので、 アクセス速度のバラつきが大きいです (脚注2) 価格 ... 最近は(最安値の単価比較で)HDDとの差は数倍ていどです。 数百GBならSSD一択でしょうが (そもそも今そんな小さなHDDって売ってるっけ?)、 十数TBとなるとHDD <br> (脚注3) SSDも大きくなってますから業務用ストレージもSSDベースが主流の雰囲気? 専業メーカーとしてはPure Storageが老舗かな </small></small> </div> <small> 1. 軽い、小さい 1. 回転部品が無いので(HDDよりは)衝撃に強い 1. ランダムアクセスが得意(脚注1) 1. 最近だいぶ安くなり実用的になりました(脚注2) </small> --- class: compact # <small>デバイスの物理的な話: SSDのデメリット</small> <div class=footnote> <small><small> (脚注1) SSDによる長期保存は危険です。 物理的に部品へ無理がかかるため、 つねに少しずつ摩耗(崩壊)している媒体です。 有名ブランドのSSDをPCの耐用年数程度(数年)使うくらいなら問題ないでしょう。 つまり普段使いなら大丈夫です。 ただしHDDのように20年ものでも使えますか?というと、おそらく無理でしょう <br> (脚注2) Q: 安いSSDとは何か? A: 怪しげなコントローラとか、キャッシュを小さくするとか... (蓋を開けたらUSBメモリだったとかな:-) </small></small> </div> <small> - 耐久性は(HDDほど)ない(脚注1)、**wear leveling**の性能が重要(脚注2) <small> - 何もしなくても少しずつ崩壊しています。読み書き自体も半導体へ負荷をかけます - 半導体への負荷を均等化することが大事、つまり 特定の場所に読み書きが集中するのは避けないといけません - 均等に摩耗するようにコントローラが調整しています (**wear leveling**; wear=摩耗) </small> - 動作原理の違いからくるデメリット。例:処理単位の大きさ、消去 <small> - HDDのセクタより大きな単位で処理しています - とくにErase(消去)は大きな単位でしか処理できません。 (HDDのような単純な)更新処理は出来ません </small> - <b>コントローラ次第</b>(脚注2) <small> - さまざまな合わせ技でSSDを動かすため、 **性能や耐久性はコントローラ**で大きく変わります </small> </small> --- class: col-2,compact # <small>デバイスの物理的な話: 磁気テープ(1)</small> <div class=footnote> <small><small> (脚注1) もはや磁気テープは日本(それも富士フィルムだけ?)しか製造しておらず、 全世界のクラウドの裏側は日本だより! <B>需要拡大中</B> <br> (脚注2) 磁気テープの価格は手頃ですが磁気テープドライブがサーバ用しかなく高価(数十万〜)なので、 個人はテープよりHDDが手頃 <br> (脚注3) ちなみにLTFSの仕様は <A HREF="#ufs">Unix初期のファイルシステム</A>そっくりでINDEXとデータを分けて管理 </small></small> </div> <small> - 容量単価、大容量性、長期保存性能という点で、 **磁気テープ**が最強の保存媒体です <small> - 現在は手のひらサイズの1巻10TB台ですが、 1巻[580TBの目処はある](https://www.fujifilm.com/jp/ja/business/data-management/data-archive/tips/merit/009)そうです。まだまだ大容量化が可能 </small> - 近年はLTFSという磁気テープ向けのファイルシステムも策定され使いやすくなりました! <small> - LTO-5規格以降なら、 (HDD/SSDをみるように)磁気テープをフォルダとして開いて操作ができます </small> </small>   --- class: compact # <small>デバイスの物理的な話: 磁気テープ(2)</small> <div class=footnote> <small><small> (脚注1) AWSは裏側を教えてくれないのですが、 AWS S3 Deep Archiveは磁気テープに書きこむから激安サービスなのではないかと疑っています。 「読み出すのに半日お待ちください」みたいな仕様なんですもの。 テープを探しに行ってるんでしょ?(w) <br> (脚注2) たしかGoogleも磁気テープでバックアップをとっています </small></small> </div> <small> - ユーザとしては磁気テープよりAWS S3などにバックアップする時代でしょう - クラウド事業者などの裏側の話をすると - 巨大ストレージのバックアップは磁気テープ一択 - オンラインストレージは容量無制限なので普通のデバイスにバックアップなど出来ません - ランサムウエア対策にもなるので需要急増中(ここは個人/法人とわず) - いったんテープに書きこんだらオフラインにする前提ですけどね </small> --- class: compact # <small>銀の弾丸などない</small> <div class=footnote> <small><small> (脚注1) HDDや磁気テープは永遠に不滅です!(は言い過ぎか?:-) <br> (脚注2) F.J.Brooks, <A HREF="https://doi.org/10.1109/MC.1987.1663532">"No Silver Bullet"</A>、 Brooksの有名な「人月の神話」新装版の第16章に日本語訳が収録されている </small></small> </div> <small> - SSDは万能ではありません <br> <b> 「新技術も特定の分野に秀でているだけで前時代の問題の全てを解決するわけではありません」 </b> - 身の回りからHDDや磁気テープがなくなることはあるかもしれませんが、 <br> **クラウドの裏や業務用サーバでHDDや磁気テープがなくなることは(当面)ありません** </small> --- class: compact # <small>【参考】データセンターが次世代のHDDに求めるもの</small> <small> - Disks for Data Centers (Google, 2016) - https://research.google/pubs/pub44830/ - ランダムアクセス性能 - 容量、代替領域は不要なので、その分も容量へ回してほしい - 継続利用性 - アーム先端のヘッドが壊れたらHDDは使えない?-> アームの先端部を冗長化してほしい - Hyperscaler Storage (SNIA, 2016) - https://www.snia.org/educational-library/hyperscaler-storage-2016 - 既存の標準規格や標準規格の改訂案がどのようにこれらの要件に対応できるかを検討 - Y. Li et.al., "Facilitating Magnetic Recording Technology Scaling for Data Center Hard Disk Drives through Filesystem-Level Transparent Local Erasure Coding" (USENIX, 2017) - https://www.usenix.org/conference/fast17/technical-sessions/presentation/li - 読み取りリトライの発生を減らすため、各HDDローカルに消失訂正符号化 - OSのファイルシステム側にも改造を... </small> --- name: pause class: compact,col-2 # <small>(アーカイブ動画で見ている人も)一時停止して休憩</small> <div class=footnote> <small><small> 「30分ごとに雑談(休憩)をしろ」というのが指導教官の教え <br> 正確には「アメリカでは30分ごとにジョークを言わないといけない」だけれど、そんな洒落乙なこと無理:-) </small></small> </div>   --- class: title, smokescreen, shelf, no-footer # ファイル管理技術<br><small><small>〜ファイル,ファイルシステム,RAID〜</small></small> <div class=footnote> <small><small> </small></small> </div> --- class: compact,img-right # <small>【概要】データの読み書き</small> <div class=footnote> <small><small> (脚注1) 分散システムは(時間があれば)次回すこし触れます (脚注2) 図の右下は少し適当で、 HDDの生イメージをテープやS3にコピーしているようにも読めます。 テープなら生コピーがありうるかもしれませんがS3はセクタではなくファイルでしか操作できません </small></small> </div> 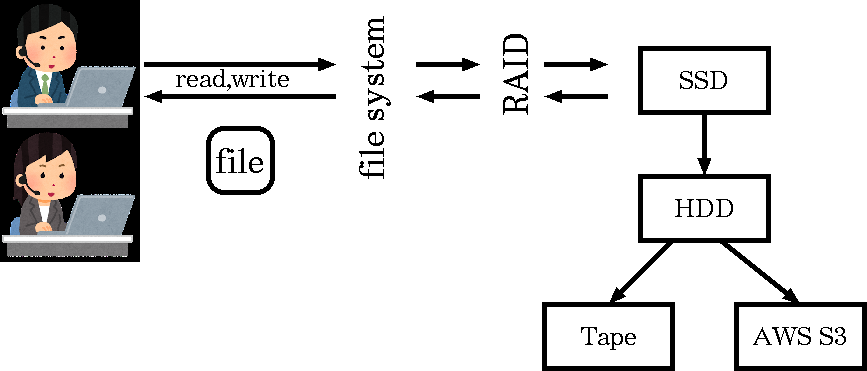 <small> - オンプレミスの業務用サーバの場合、 読み書きは図のように様々なシステムを経由して、 最終的にSSDやHDDに書きこまれます - 図のような多段構造があります - これをうまく運用できると良い - OSレベルの「ファイルシステム」 - ファイルシステムが操作するハードウエア - HDDやSSDを(直接)操作 - RAIDというHDD,SSDの塊を操作 </small> --- class: title, smokescreen, shelf, no-footer # <small>ファイルとファイルシステム</small> <div class=footnote> <small><small> </small></small> </div> --- class: col-2,compact # <small>【用語】</small> <div class=footnote> <small><small> (脚注) 【基本情報試験の出題範囲】 (a)HDDは動作原理も含む (b)入出力装置や補助記憶装置の各種デバイスについての名称くらい </small></small> </div> <small> - **主記憶装置** ... メインメモリ - **補助記憶装置** - **HDD** (ハードディスク) - **SSD** (**Solid State Drive**) - FD (フロッピーディスク) - 光ディスク(CD-ROM,DVD,BD) - **磁気テープ**(DAT) - USBメモリ,SDカードのたぐい <wbr> - Unix上でのデバイスの分類 - **ブロックデバイス** ... ブロック単位での読み書きをするデバイス - 代表的な単位はHDDのセクタ=512バイト - 例:HDD、SSD - **キャラクタデバイス** ... 低速のデータ転送<br>(1文字ずつのスピード感) - ブロックデバイスの対極、入力デバイスが典型。例: キーボード,マウス,ジョイスティック,スキャナー,バーコード </small> --- class: col-2,compact # <small>ファイルのデータ表現(半分は復習)</small> <div class=footnote> <small><small> (脚注) 21世紀のデファクトスタンダードは、 <b>Unicode</b>で定義された数字(code point)を<b>UTF-8</b>方式でエンコードした数字列。 <br> 表示の際は、 その数値を解釈し、該当する日本語フォントで表示します。 例:あ = 3042 (code point)、343 201 202 (UTF-8) </small></small> </div> <small> - ファイル ... 数字の**バイト列**を格納するもの - **データストリーム** - プロトコル - 改行や空白(SPACEやTAB)を意味するコードを入れておき、 テキストを表示するプログラム(エディタやブラウザなど)が適切に表示 - Q: 日本語は? A: UTF-8 (脚注) </small>   ``` HAMLET To be, or not to be, that is the question, Whether 'tis nobler in the mind to suffer ... 以下略 ... ``` --- class: col-2,compact # <small>Unix上でのファイルという論理構造(or 概念 or プロトコル)</small> <div class=footnote> <small><small> (脚注) 実際にファイルを操作する手段はファイルシステムが提供します。 システムコールでカーネルにファイルの操作を依頼します </small></small> </div> <small> - ファイル=**メタデータ**+**データ(本体)** <small> - Protocol Header = メタデータ - Protocol Payload = データ (例: Cのソースコードそのもの、テキストつまりUTF-8の数字の列) </small> - ファイル操作の例 <small> 1. ファイル名の変更(a.c -> b.c) <br> メタデータのみを書き換え <br> (ファイル名と最終参照時刻を変更) 1. ソースコードを書き換える場合 <br> データそのものの書き換え + メタデータを更新 <br> (サイズや最終参照時刻、最終更新時刻などを変更) </small> <wbr> | 属性 | 備考 | |------------------ |-------------------- | | ファイル名 | 文字列 | | ファイルの長さ | バイト数 | | 所有者のID | uid(数字) | | 所有者のグループ | gid(数字) | | ファイルモード | いわゆるpermission | | 最終参照時刻 | unixtime | | 最終更新時刻 | unixtime | | データ格納位置 | セクタ番号(群) | 表: メタデータの例 </small> --- class: img-right,compact # <small>ファイルを管理する(無限階層)本棚</small>    <small> - ファイルは本で、ディレクトリ(フォルダ)は本棚 - 本の奥付 = メタデータ - 例:タイトルや著者、出版日など - 本の中身 = データ(ファイルの本体) - 本棚の中に本棚を作れます - 無限本棚 - 無限マトリョーシカ - つまり階層化されています - 棚のなかを区切り、本棚の階層(入れ子構造)が作れます。 深い階層化も可能です </small> --- class: img-right,compact # <small>階層型ファイルシステム</small> <div class=footnote> <small><small> (脚注1) DNSのほうが後なので、正確にはDNSがUnixファイルシステムをリスペクトしている? <br> (脚注2) 大型計算機のファイルシステムは一階層なので本当に本棚みたいに見えます </small></small> </div>  <small> - Unixのファイルシステムの特徴 - 木構造 - DNS(右図)と同様です - 階層型ファイルシステム - 階層型ファイルシステム以外 - 大昔の大型計算機 - スマートフォンの見栄えは非階層(裏側は階層型ファイルシステム) </small> --- class: img-right,compact # <small>Unixファイルシステム: ディレクトリ(フォルダ)と木構造</small> <div class=footnote> <small><small> (脚注1) rootからの木構造は(/を.にすれば)DNSと同じなので分かりますよね? (脚注2) Windowsの遠いご先祖MS-DOS 2.0でUnixの設計思想を大々的に取り入れたのですが、 MS-DOS 1.0のオプション記号/を維持するために、MS-DOSは区切りに/ではなく\を使い大迷惑 (\はC言語で特別なのに...) (脚注3) T.Berners-LeeがURLを/区切りにしたのはUnix互換OS上での開発だからだと思う(推測) </small></small> </div>  <small> - ファイルをおさめる入れ物をUnix系では**ディレクトリ**、 Windowsなどでは**フォルダ**と呼びます (以下Unixの話をします) - ディレクトリは**入れ子**にでき**、木構造**を構成 - ディレクトリの中に、ディレクトリもファイルも入れられます - Unixでは/で階層の区切りを表現します。 階層の一番上は**/**でrootと呼びます - たとえば/usr/bin/viは図(の網線部の)ような階層をあらわしています </small> --- class: img-right,compact # <small>Unixファイルシステム: 表現形式、パス</small> <div class=footnote> <small><small> </small></small> </div>  <small> - Unixでは/で階層の区切りを表現します - 階層の一番上は**/**でrootと呼びます - <b> 区切りも/、一番上も/ <br> これが初心者を困らせる何か? </b> - たとえば/usr/bin/viは図(の網線部の)ような階層をあらわしています - ファイルの位置を表現する/usr/bin/viのような表記を<b>パス(path)</b>と呼びます </small> --- class: img-right,compact # <small>絶対パス、相対パス、cdコマンド</small> <div class=footnote> <small><small> (脚注1) パスの問題は意外と基本情報処理に出ます <br> (脚注2) ./viは、そのディレクトリにあるviコマンドを実行という意味です。 コマンド検索時に.を探さないのがdefaultなので./が必要 </small></small> </div>  <small> - **絶対パス** ... **/**(root)からの階層をすべて表現 - **相対パス** ... 作業中の場所からの相対表記 - ディレクトリの移動はcdコマンドの引数にパスを書きます。 **.** (自分自身)と**..** (一つ上,親ディレクトリ)は特別なパスです ``` /usr/bin/vi # #の右側はコメントです cd /usr/bin # /usr/binに移動して ./vi # viを起動(/usr/bin/viの起動と同じ意味) cd .. # 一つ上に移動したので今いる場所は/usr ./bin/vi # viを起動(/usr/bin/viの起動と同じ意味) ``` </small> --- class: compact # <small>ディレクトリ: lsコマンドでの表示<small>(前頁の図と比較してください)</small></small> <div class=footnote> <small><small> (脚注1) この例で使っているlsコマンドは、 対象がディレクトリの場合、 右端に/を追加して表示しています <br> (脚注2) オプションなしlsコマンドは名前一覧のみを表示、 -l オプションをつけると最重要なメタデータ情報とともに表示します </small></small> </div> ``` prompt> ls / altroot/ boot.cfg home/ libdata/ netbsd root/ tmp/ bin/ dev/ kern/ libexec/ proc/ sbin/ usr/ boot etc/ lib/ mnt/ rescue/ stand/ var/ prompt> ls -l / ... 省略 ... drwxr-xr-x 2 root wheel 1024 May 12 22:15 bin/ -rw-r--r-- 1 root wheel 172 May 12 22:15 boot.cfg drwxr-xr-x 30 root wheel 2560 Oct 23 10:04 etc/ ... 省略 ... drwxr-xr-x 15 root wheel 512 Oct 20 09:59 usr/ drwxr-xr-x 25 root wheel 512 Oct 8 21:12 var/ permission ユーザ グループ サイズ 最終更新時刻 ファイル名もしくはディレクトリ名 ``` --- class: title, smokescreen, shelf, no-footer # <small>OSや運用レベルでの工夫</small> <div class=footnote> <small><small> </small></small> </div> --- class: col-2,compact # <small>事例:4.2BSD FFS (Fast File SYstem)</small> <div class=footnote> <small><small> (脚注1) FFSの原論文(PDF,1984): [1] <A HREF="https://dsf.berkeley.edu/cs262/FFS.pdf"> M.K.McKusick and W.N.Joy </A> [2] <A HREF="https://dl.acm.org/doi/pdf/10.1145/989.990"> M.K.McKusick et.al. (ACM) </A> <br> FFSで劇的に高速化。 4.2BSDはTCP/IPとFFSという売りが多い有名なUNIXバージョン <br> (脚注2) この話は、もちろんSSDには関係ありません;-) (脚注3) この発想の元ネタはPWB UNIXにあるらしいです </small></small> </div> <small> - HDDは回転する金属の円盤なので、その構造を意識した読み書きをすれば速くなるはず - たとえば、書きこむ際、 アームを極力動かさずにすむ配置を考え、 なるたけデータを同心円上に配置していきます - アームを直径方向には動かさず、円周に沿って読み書きするのが効率的です。 アームを上げて下げる必要がある場合は、上下の時間差と回転する分を考えてデータを配置しておきます </small></small>   --- class: img-right,compact # <small>事例:ファイルシステムレベルでの障害対策</small> <div class=footnote> <small><small> (脚注1) (ファイルシステム版)RDBMSのreflog (脚注2) FFS以前の<A HREF="#ufs">Unix初期のファイルシステム</A>は障害に弱いです <br> (脚注3) FFSの作者M.K.McKusickによる上述のような改善案として<A HREF="https://www.usenix.org/legacy/publications/library/proceedings/usenix99/full_papers/mckusick/mckusick.pdf">Soft Updates</A>があり、現在のBSD系ではデフォルトです </small></small> </div>  <small> - 電源断などの非常事態からの復旧を容易にする工夫もあります - メタデータの書き込む順序の最適化 - ジャーナリング ... メタデータやデータ変更履歴を記録(右図) - 【注意】 これらは<b>中途半端な状態にならない(一貫性を維持する)努力であって、 <b>ハードウエア障害でデータがなくなることは避けられません</b> - データの消失をふせぐためには冗長化が必要で、 そのために[RAID](#RAID)や分散システムを利用 </small> --- class: compact # <small>事例:【運用】データを確実に長期保存する</small> <div class=footnote> <small><small> (脚注1) データ作成に費やされた人間の時間は貴重なので確実にデータを保存したい! (脚注2) 分散システムは次回すこし取り上げる予定です (脚注3) ランサムウエア対策としてもマメなバックアップは重要で、 バックアップしたものはREAD ONLYにできるとなおよし </small></small> </div> <small> - データの保存(確実な読み書き)はOSの最も重要な機能の一つです - 障害対策の例 <small> - ハードウエアでの耐障害性向上 -> **[RAID](#RAID)** <small> - サーバ機材では専用ハードウエア(RAIDカード)の利用が普通です </small> - ソフトウエア(ミドルウエア)による冗長化 - Googleに代表される分散システム (ネットワーク接続された安価なコンピュータ群で構成) </small> - 【運用】定期**バックアップ**は基本 <small> - 手動より自動がよい。 現代では保存先としてAWS S3やGoogle Driveなどの**オンラインストレージ**も選択できますが、 <br> 利用には十分なネットワーク帯域が必要だし、 外部におく以上セキュリティには一層きをつけないといけません </small> </small> --- class: img-right,compact # <small>事例:【運用】ストレージの階層化</small> <div class=footnote> <small><small> (脚注1) ホットデータ、コールドデータという表現があります (脚注2) SSDとHDD間で自動的に移動する製品(NASとか)が売られてますね。 自動化されていたら便利ですけど、 カーネルに実装しなくてもメタデータを見て適切に移動させるデーモンを書けばok <br> (脚注3) 例:AWS S3 -> S3 Deep Archive -> S3 Glacier(=氷河)。 アクセスを見て自動的に移動させる設定も出来ます </small></small> </div>  <small> - データにも**参照の局所性がある**ので、よく使うファイルはストレージのごく一部です - SSD -> HDD -> 磁気テープの順に**大容量**ですが、その順に**低速**になります。 そこで、 まずは**SSDに読み書き**し、一ヶ月アクセスがないファイルはSSDからHDDへ移動し、 HDD上で3ヶ月アクセスがないファイルはHDDから磁気テープやAWS S3へ移動するといった運用が理想です(脚注2) - これも一種の多段キャッシュ構造です </small> --- name: RAID class: title, smokescreen, shelf, no-footer # RAID<br><small><small>- Redundant Arrays of Inexpensive Disks -</small></small> <div class=footnote> <small><small> (脚注) 本来はInexpensive Disksですが最近はIndependentの略と称することも </small></small> </div> --- class: compact # <small>RAID (Redundant Arrays of Inexpensive Disks)</small> <div class=footnote> <small><small> (脚注1) Redundant Arrays of Inexpensive Disks つまり Inexpensive (安い)という用語のとおりです <br> (脚注2) RAIDレベル 2 3 4 は定義されていますが製品を見たことがありません </small></small> </div> <small><small> - 本来は**安いHDDをたくさんつなげて大きなHDDを作りたい**という動機 - 1980年代後半の話でRAID 0などは、まさにそれ - データの**冗長化**->耐故障性向上;サーバ機ではHDD障害にそなえてRAIDを組むのが基本 - 実務では専用ハードウエア(RAIDカード)の利用が普通ですが - 個人用であればソフトウエア(カーネルの機能)でも十分な速度です - RAIDの名称はレベル,よく見るレベルは0 1 5 6および10(いちぜろ) </small></small> | レベル | 概要 | 冗長性 | 利用可能な最大容量 | コスト | |-------- |---------------------------------- |-------- |-------------------------------- |---------- | | 0 | ストライピング:分散して書き込む | なし | 1 | 安価 | | 1 | ミラーリング:2個のDISKに同じデータを書きこむ | あり | 1/2 | 高価 | | 5 | データとパリティを書き込む | あり | (HDD数-1)/HDD数e.g.2/3 | やや高価 | | 10 | RAID1群を作成後それらをRAID0で束ねる | あり | 1/2 | 高価 | --- class: col-2,compact # <small>RAID 0および1</small> 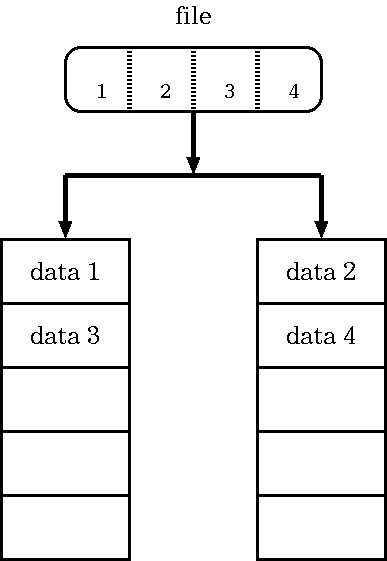 RAID 0 = ストライピング: 大容量かつ(HDDの並列動作で)高速化が可能ですが、HDDが1つ壊れるだけで全滅。 キャッシュなどの一時領域としては便利ですが、保存領域に使ってはいけません  RAID 1 = ミラーリング: 二つの HDD に同時に同じデータを書きこむ。 簡潔な理屈のため回路も簡単で信頼性が高いが、 HDDの半分しか使えない高価な手法。 読むときは2つのHDDから読みこむことで倍速が可 --- class: compact # <small>RAID 10</small> <div class=footnote> <small><small> (脚注) RAID 10は数字の10(ten)ではなく1と0です </small></small> </div>  RAID 1のセットを作り、それらをRAID 0で束ねることで高速化と大容量化が可能 <br> メリット: RAID 0と1のメリットのいいとこ取り <br> デメリット: RAID 1と同じでHDD数の1/2しか利用できない高価なところ --- class: img-right,compact # <small>RAID 5および6</small> <div class=footnote> <small><small> (脚注) RAID5の障害時からの復旧は、 壊れたHDDを新しいHDDに交換し、パリティを利用したHDDの再構成を行いますが、 この処理が非常に高負荷のため、 この負荷により別のDISKも壊れて結局HDDが全滅することがあります(実話) <- parity系RAIDがきらいな由縁 </small></small> </div>  RAID 5 = RAID 1と0の妥協点とも言え、復旧するためのパリティデータを分散配置 (HDDが1台なら壊れても大丈夫、2台こわれたら全滅)。 パリティにHDD 1台分が使われますがRAID 1ほど高価な方法ではないため、よく見かけます。 例: 合計3台のHDDなら2個分、合計4なら3個分の容量が利用可能 RAID 6 = RAID 5 の拡張でパリティを二重にもつ方法です。 HDDの総容量はRAID 5より少なくなりますが故障には強くなります。 最近は 6 を見ることが多い気がします --- name: appendix class: title, smokescreen, shelf, no-footer # <small>付録</small> <div class=footnote> <small><small> (脚注) これ以降は中間試験に出ません </small></small> </div> --- name: ufs class: img-right,compact # <small>参考: ファイルシステムの例(Unixの初期, 1970年代)</small> <div class=footnote> <small><small> (脚注1) 中間試験には出ません (脚注2) inodeはサーバのデバッグに必要な知識ですが、 OS各論すぎるので情報処理試験には出ません。LPICでは出題されます。 さすがにレイアウトの詳細までは出題されない模様 </small></small> </div>  <small> - HDDは512バイト単位のsectorという配列と考えてください - セクター0(sector[0], 先頭の512バイト)にはOS起動時に使う特別なデータを格納 - セクター1はHDDのlayoutなど設定情報が入っています(superblock, 詳細は略) - セクター2から**inode構造体**配列が並び、 その後にデータが並んでいます(図ではセクターN以降がデータ): 各inodeが持つデータは (a)メタデータ (b)該当するファイルやディレクトリのデータを格納しているセクタ番号群(必要なだけ複数個) </small>