class: title, smokescreen, shelf, no-footer # <small>情報技術応用特論 第05回<br>OS(2): OSの中核部分</small> <div class=footnote> <small><small> Copyright (C) Ken'ichi Fukamachi <fukachan@fml.org>, 2021-2025. CC BY-NC-SA 4.0 </small></small> </div> --- class: img-right,compact # <small>シリーズ構成、サーバの全体像との関係</small> <div class=footnote> <small><small> (脚注) 「カーネル」「WWWサーバプロセス」はプロセスの一つ <br> 「スケジューラ」はプロセス制御のくだりで登場しますが、それくらいか? </small></small> </div> 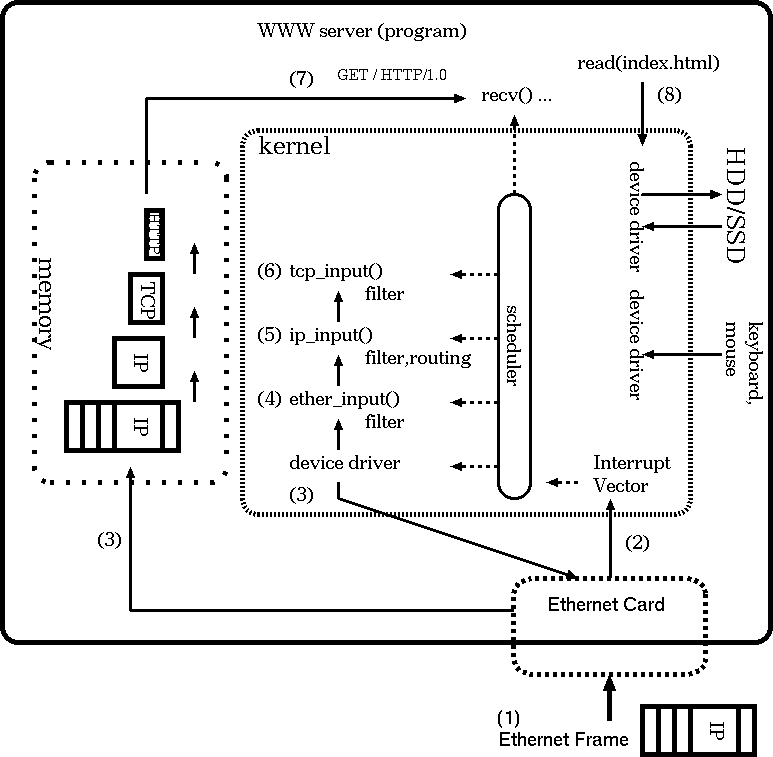 <small> - シリーズ構成 - 第05回 - CPU - プロセス - メモリ(仮想記憶) - 割り込み - 第06回 - 競合状態と排他制御 - デバイスドライバ - ストレージ - 今回(第05回) - 前半2/3(CPU〜メモリ)は図の裏側にあるハードウエアや仕組みの話と言えます </small> --- name: cpu class: title, smokescreen, shelf, no-footer # CPU <div class=footnote> <small> </small> </div> --- class: img-right,compact # CPU動作の概要 <div class=footnote> <small><small> (脚注1) レジスタがあるので、CPUは電卓より少し賢い動作ができますが、 大雑把にはCPU=超高速な電卓というイメージです。 <br> (脚注2) 電卓だけあっても、記憶装置などの周辺機器が無いと、ぜんぜん便利な機械では無いです </small></small> </div> 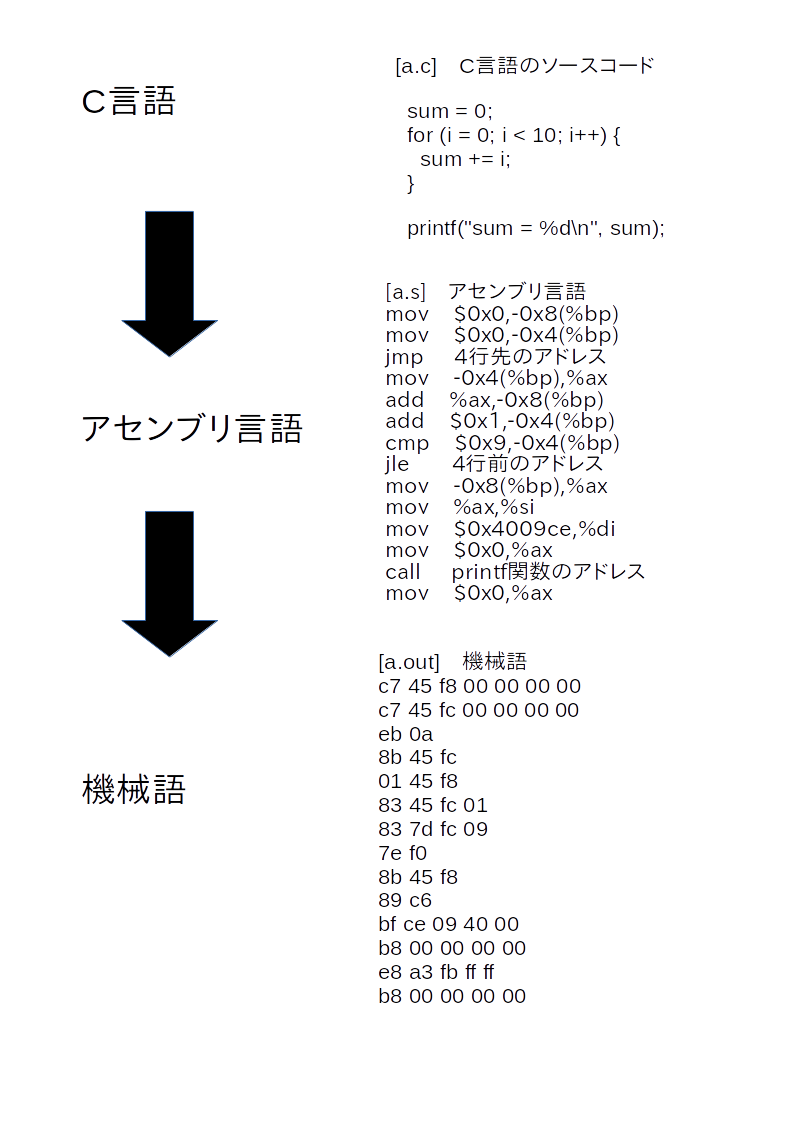 <small> - 演算と制御装置(五大要素) 1. プログラムを**入力装置**から 1. メモリ(**記憶装置**)へ読み込み 1. メモリ上の**機械語**を順次実行 - 実行時の一時領域などには**レジスタ** (CPU内の小さいが高速な記憶領域)を使い様々な処理をしています - CPUが解釈できるのは**機械語**だけです - **コンパイル**とは機械語への翻訳です 1. ソースコード(例:i=0) -> 1. アセンブリ言語(例:mov $0,ax) -> 1. 機械語(マシン語,例:0xb800) </small> --- class: img-right,compact # <small>機械語を1対1翻訳したものがアセンブリ言語</small>  <div class=footnote> <small><small> (脚注1) 授業では、これ以上の詳細は割愛しますが、 基本情報処理試験の範囲は意外と広く、 レジスタやアセンブリ言語も、もう少し細かいところまで求められます。 例: アドレス指定の直接,間接,相対(アドレス指定) ... C言語のポインタのポインタといったポインタまわりの機械語表現のようなもの (脚注2) 基本情報の午後の部では簡易化したアセンブリ言語でも受験できます。 実はアセンブリ言語を選択するのが(難しい文法がないし)一番簡単といううわさ有り <br> (脚注3) 昔の映画のように「科学者が紙テープを読む(右図)=機械語を生読み」なんてしません(w) </small></small> </div> <small> - 機械語は数字(前頁参照)ですが - 人間が機械語を直接読み書きするのは辛い - アセンブリ言語で読み書きします/できます - これは**機械語を1対1翻訳した**言語 </small> --- class: compact # 例: アセンブリ言語 <div class=footnote> <small><small> (脚注) アセンブリ言語でループを解説する例が<A HREF="#register-details">付録</A>にあるので参照してください </small></small> </div> <small> ``` 例: siレジスタへaxレジスタの値をコピーする 機械語 <-> アセンブリ言語 // 解説 (機械語より、だいぶ読みやすいよね?) 89c6 mov %ax,%si // movが命令部、%ax,%siがオペランド部 // これはAT&T記法、Intel記法(この例はmov si,axになる)もあります // 授業で使っているGCC(GNU Compiler Collection)はAT&T記法 [むりにC言語っぽい記述をすれば] register ax, si; register_copy(ax, si); ``` - 機械語(マシン語): a.outを生で読むと 89c6 のような数字が並んでいます - アセンブリ言語では、CPUの1命令が1行ずつに翻訳/出力されています - 89がmov命令(注:moveの略ですが実際の動作は<b>コピー</b>です) - c6の部分がaxレジスタとsiレジスタ - あわせると`mov %ax,%si`(movが関数名、引数が%axと%siと思えばよい;スペース区切り) </small> --- class: compact # クロック周波数とコア数、その歴史的展開 <div class=footnote> <small><small> (脚注1) (後述するパイプラインやRISCの工夫でも速くなりますが) クロック数=1秒間に実行できる命令数が増えれば、そのぶん確実に速くなります (脚注2) 2000年代前半のIntel Netburstアーキテクチャ(製品例:Pentium D)。 クロック数を上げることはできても、3GHzあたりを越えると、 使うエネルギー(電力)=発熱のわりに高速化しなくなってきたというのが当時の見解です。 いまのCPUの最大クロックは、もう少し大きいですが、それでも数GHzが最大です (脚注3) 個人向けPCではコア数個でしょう。 業務用サーバでは、コア数が64〜128個などの製品が使われています。 仮想環境を提供するサーバ(いわゆる仮想母艦)では、 サーバの物理的な体積あたりのパワーが大きい方が良いです。 データセンターへのサーバの収容効率が良くなるから(-> プロバイダの経営の話) </small></small> </div> <small> - **クロック周波数** <small> - 電圧の上がり下がりが処理の基本単位になっていて、 各部品間のタイミング合わせをしています。 これが<b>クロック</b> - CPU内部の周波数が**内部クロック**、 CPU外部(いわゆるバス)は**外部クロック**で内部より数倍おそいです </small> - **内部クロックをあげる=高速化**につながりますが、 2000年代後半以降は**コア数**を増やして性能を向上 <small> - **クロック数による高速化は3GHz付近で限界点に達した**(脚注2) - このあとの世代、いわゆる**Intel Coreアーキテクチャ**では、CPU単体のクロック数は3GHz付近までで、 プロセッサ(手のひらサイズのLSI)に(旧)CPU複数個分をいれるようになりました (この個数が**コア数**) </small> </small> --- class: compact # <small>CPUの大設計方針</small> <div class=footnote> <small><small> (脚注1) CISCはCompilicated Instruction Set Computer、RISCはReduced Instruction Set Computer の略 <br> (脚注2) かつてコンピュータの性能が低かった時代には、 一発の命令でハードウエアつまりCPUに複雑な仕事をやってもらうほうが良いと考えられた時代があって、 CISCは、その産物と考えられます。 しかしながら、 CPUの使い方を実測してみると、複雑な命令の使用頻度は低いことが分かりました。 大変な思いをしてCISC CPUを作りこむメリットが無いことが判明したわけです <br> (脚注3) 商用インターネット時代の主流はRISC系です </small></small> </div class=footnote> - **CISC** = **多数の命令語**があるCPUの設計 <small> - 複雑な処理が出来る命令群 </small> - **RISC** = **命令語が少なめ(厳選)の設計** <small> - 単純な命令群 - このほうがパイプライン(後述)に適しています - 最適化はコンパイラが頑張ります - (集積密度があがり複雑化する一方の)CPUの設計が楽になります </small> --- class: compact # <small>CPUの高速化技術</small> <div class=footnote> <small><small> (脚注) さらにステージを細かく分けるスーパーパイプラインや、 パイプラインを複数もつスーパースカラという技術も使われています。 これらは基本情報の範囲ですので、各自で勉強してください:-) </small></small> </div class=footnote> <small> - 逐次制御 ... 機械語を順番に実行します - **パイプライン** ... 機械語の命令を平行して実行します - 命令の内容によっては必ずしも逐次実行する必要が無いことを利用します - 例:「メモリから読み込む」「加減乗除」は全然別の処理です - 可能な限りCPUの全部品に仕事をさせたい(遊ばせない) -> 効率化=速度向上 - うまくいけば並列処理をしているかのように速くなります 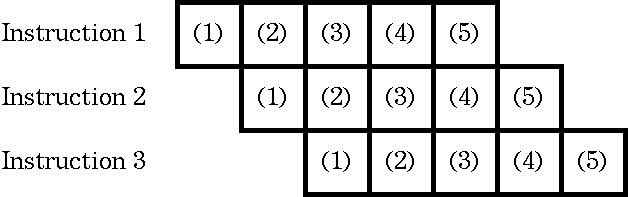 </small> --- class: col-2,compact # GPU <div class=footnote> <small><small> (脚注1) GPUこそRISC的な発想の路線上にあると言えるよね?RISC CPUよりはるかに単純で並列度が高い部品ですけど <br> (脚注2) いまどきのGPUボード上位機種なら並列実行できる演算器を数千個〜数万個は搭載しています <br> (脚注3) 電力効率の高いスパコン ... 例: 数世代前の話ですが、 東工大のTSUBAMEはNVIDIA GPUを大量に並べたスパコンで、 GREEN500(速度/電力の勝負,2013)でTOPでした (TSUBAMEは「みんなのスパコン」で、 <A HREF="https://www.titech.ac.jp/">東工大</A> の人は誰でも使えたらしい、いいな〜 <br> (脚注4) 本当に「コストパフォーマンスがよい(?)」かはGPUベンダからの仕入れ値しだい。 そもそもスーパーコンピュータ自体が一品物/特殊案件で、 普通の仕入れ値ではないはずだから、正直よくわからないです。 法人向けビジネスなんて全部そんなものなので:-) </small></small> </div> <small> - GPU - 画像処理に特化した浮動小数点演算を並列実行できるプロセッサ - GPGPU (Generic Purpose GPU) - 画像処理以外の分野に流用すること - 機械学習 - 暗号解読 - データマイニング <wbr> - [応用]スーパーコンピュータ - 科学技術計算は浮動小数点演算なので、 GPUボードを束ねればスーパーコンピュータになります - 電力効率が高い(**省電力**) - コストパフォーマンスがよい(?) </small> --- class: title, smokescreen, shelf, no-footer # プロセス <div class=footnote> <small> </small> </div> --- class: img-right,compact # <small>【用語】仕事の処理単位</small> <div class=footnote> <small><small> (脚注) 汎用機文化には「ジョブを流す」と言う言い回しがあります。 この手の用語の話(いわゆる宗教戦争っぽい話)は、 どちらかというと汎用機とか規格を決めたがる人たちの文化の雰囲気があります。 実際、Unix用語ではjobとtaskとprocessをきちんと分けて使い分けてないですし... (例: processから起動したjobのcontrol) </small></small> </div>  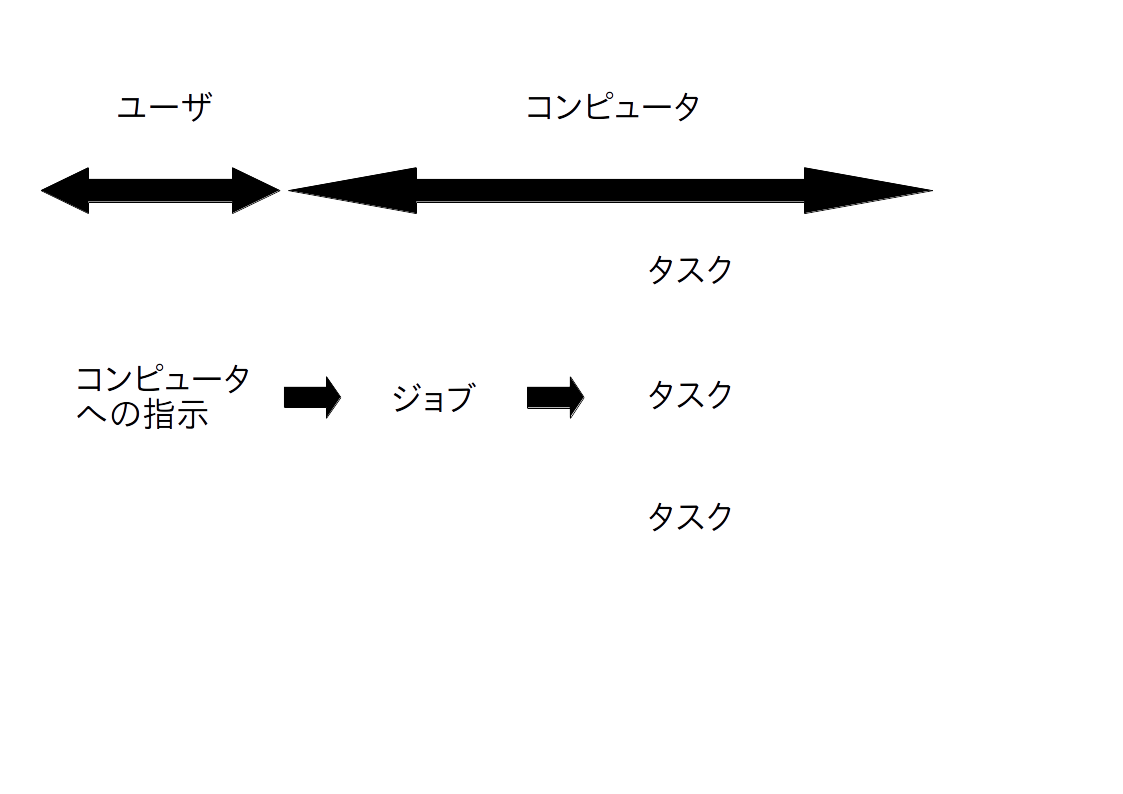 <small> - コンピュータ->**ジョブ**->**タスク**と細分化 - **ジョブ**=ユーザがコンピュータに指示する単位、 **タスク**は**ジョブ**を分解したものでコンピュータからみた仕事の単位 (そういう用語があります) - 以下、本稿ではOS上での仕事の単位を**プロセス**と呼びますが、 OS内部を解説する本稿の文脈ではタスクとプロセスは同義語です <br> (Unixではプロセス、(Mach由来の)MacOSXやWindowsではタスクと呼んでいます) </small> --- class: img-right,compact # <small>【用語】Unixにおけるプロセス</small> <div class=footnote> <small><small> (脚注1) プロセスの詳細は覚えなくてOK。 若干の解説あり -> 付録を参照 <br> (脚注2) ユーザプロセスを動かす環境を<B>ユーザランド(userland)</B>と呼びます。 システム構築演習とは、ほぼ<b>ユーザランドの操作</b>です </small></small> </div>  <small> - プログラムが動く際には次のようなデータやメモリ領域、CPUの設定、管理情報が必要で、 これらの総体を**プロセス**と考えてください - プロセスの構成要素<small>(右図については後述)</small> <small> - **メモリ**上に置かれたコード(プログラムの命令の実体,**TEXT領域**) - **メモリ**上の変数や**スタック**領域 - **仮想記憶**システムの管理情報 - CPUの**レジスタ** - 開いているファイルの情報など </small> </small> --- class: img-right,compact # <small>【用語】Unixにおける特権プロセス</small> <div class=footnote> <small><small> (脚注1) ユーザプロセスを動かす環境を<B>ユーザランド(userland)</B>と呼びます。 システム構築演習とは、ほぼ<b>ユーザランドの操作</b>です </small></small> </div>    <small> - プロセスには**特権**あり/なしの2種類 <small> - 図(右)のような階層モデルで**内側が特権(中央がkernel、外がuser)**と考えています </small> - **カーネル (kernel)** ... 特権あり - ユーザ (user) ... 特権なし <small> - たとえ話:システム構築とはイースターエッグに色を塗っているようなものではないでしょうか?:-) </small> </small> --- class: img-right,compact # <small>プロセスの状態遷移とマルチプログラミング</small> <div class=footnote> <small><small> (脚注1) いまどきは「実行状態プロセス==コア数」です(コア数が1の場合、プロセスは一つだけ) (脚注2) つまりアニメと一緒です:-) </small></small> </div>   <small> - プロセスには3つの状態があります: **実行可能状態、実行状態、待ち状態**(右上図) - ある瞬間の**実行状態プロセスは一つだけ**です - (カーネルの中の)**スケジューラ**が、どのプロセスを実行するかを決定しています - たとえば1/100秒ごとに実行状態プロセスを切り替え、 人間の目にはプロセスが同時実行されている幻影をみせています。 <br> この動作を**マルチプログラミング**もしくは**マルチタスク**と呼びます(右下図) </small> --- class: img-right,compact # <small>スケジューラとスケジューリングアルゴリズム</small> <div class=footnote> <small><small> (脚注) 教科書的な説明をするなら、 schedulerが順番を決めて、 切り替えをするのがdispatherとか、 きちんと用語を使い分けないといけないのでしょうが、 実際のカーネルコードが綺麗に書き分けてるとも限らないので、 このへんは端折ってます </small></small> </div>   <small> - 選ぶ方法=**スケジューリングアルゴリズム**の例 <small> - ラウンドロビン方式 ... 順番に一定時間で代わりばんこ - **優先度方式** ... プロセスごとに優先度という概念があり、 再計算して適切なものを選ぶ。 「**対話的プロセスを優先**」などの細かい調整が出来るのでTSS向き </small> </small> --- class: compact # <small>マルチプログラミングのメリットとデメリット</small> <div class=footnote> <small><small> (脚注1) タイムシェアリングシステム(TSS)はコンピュータを対話的に使う方法です。 OSはキーボードやマウスからの入力を待ち、処理し、結果を出力しています。 人間の操作(キーボードやマウス)、HDD、CPU間には数億倍の速度差があります。 例えば、キーボード入力を一文字待つあいだにCPUは数億回の足し算ができます </small></small> </div> <small> - メリット:OS全体での**利用効率向上**です <small> - あまりにも違う**デバイス間の速度の差**を相殺できます。 - プロセスAが待ち状態のときにプロセスBを実行すればCPUが遊んでいる時間がなくなります <br> 例:プロセスAが「キーボード入力待ち」や「HDDへの入出力待ち」をしている時、プロセスBを実行できます </small> - デメリット:プロセスの切り替え(**コンテキスト切替**)(後述)のオーバヘッドです <small> - TSSでは、 このオーバヘッドがあっても、メリットのほうが大きいと判断されているわけです </small> </small> --- class: img-right,compact # <small>コンテキスト切り替え</small> <div class=footnote> <small><small> (脚注1) コンテキスト切り替えは、英語でcontext switchです (脚注2) 基本情報レベルでは<B>太字の用語だけでOK</B>です。 (脚注3) この説明も端折ってますが、 実際のカーネルコードを読まないとcontext switchの技術詳細は分からないと思います (でもオオゴトになるので割愛)。 モヤモヤする人はUnix kernelのソースコードを読んでね。 細部はOSバージョンやCPUごとに微妙な差異がありえます </small></small> </div>  <small> - プロセスの構成要素をコンテキスト(context)と呼んでいます。 これはプロセスを再現できる制御情報のすべて(プロセスの総体と同義)です <small> - CPUレジスタの値,メモリ管理情報,カーネルのもつプロセス制御情報,ファイル他 </small> - **コンテキスト切り替え**とは <small> - プロセス1のコンテキストを保存 - プロセス3のコンテキストを読み出し再設定 - プロセス3を実行する(= 3に切り替える) </small> </small> --- class: img-right,compact # <small>プリエンプション(Preemption)</small> <div class=footnote> <small><small> (脚注1) <b>割りこみ</B>(interrupt)は、このあと解説します <br> (脚注2) カーネルも(特権を持っていますが)単なる一つのプロセスです。 カーネルプロセスに切り替えないとOSの管理が出来ません </small></small> </div>  <small> - **プリエンプション**(Preemption) - Preemptとは強引に横取りすること - 割り込みの例 <small> 1. (割りこみがかかると) プロセス1がPreemptされ<b>強制的に処理が一時中断</b>されます 1. 割り込みの仕事をするプロセスへ切り替えが起こり ... (以下略) </small> </small> --- class: img-right,compact # プロセスのメモリ空間レイアウトの例 <div class=footnote> <small><small> (脚注1) 応用情報のレベル (脚注2) <B>メモリレイアウトの詳細を気にしなくてOK(OSの有り難味)</B> </small></small> </div>  <small> - 右図のアドレスは下が小さく(0)->上が大 - 理論上の最大値は32ビットCPUが4GB(=32bit)、64ビットは16EB - レイアウト(上から下へ解説) <small> - 上から下へ**スタック**領域が伸びる <br> (関数呼び出しやローカル変数で利用) - 真ん中あたりは未使用 - データやローカル変数(mallocするもの)の領域 - アドレスの小さい側にTEXT領域 - みなさんのa.outの実体はここ - 0バイト付近には割り込みの定義 </small> - **どのプロセスでも同じレイアウト**です。 衝突しないの? これは物理ではなく**仮想メモリアドレス**なので衝突しません (-> 「仮想記憶」節を参照) </small> --- class: col-2,compact # <small>【参考】【余談】きみはコンテキスト切り替えがイメージできるか?</small> <small> - 次の動作をイメージしながらkernelソースコードが読めるか?/納得できるか?次第で、 **OS動作の分かりづらさ**が変わってくると思います 1. 並列実行されているかもしれない 1. 突然、任意の場所で中断/再開がありうる  <wbr> - いまどきのOSはFully Preemptiveに書かれていて、 [アセンブリ言語](../cpu/#disassembled-loop) の任意の場所(行単位)で中断がかかります - C言語で表現すると、 一行単位どころではなく一行の途中で突然中断し再開がいつか?も不明な振る舞いです (C言語をアセンブリ言語に翻訳すると一行が数倍に膨れ上がるのが普通で、 そのアセンブリ言語の任意の行で中断/再開します。 左のコード例でいえばforループの条件部`i < 10`ですら条件判定の途中で中断がありえます) </small> <div class=footnote> <small><small> (脚注) このページは中間試験に出ません:-) </small></small> </div> --- name: pause class: compact,col-2 # <small>(アーカイブ動画で見ている人も)一時停止して休憩</small> <div class=footnote> <small><small> 「30分ごとに雑談(休憩)をしろ」というのが指導教官の教え <br> 正確には「アメリカでは30分ごとにジョークを言わないといけない」だけれど、そんな洒落乙なこと無理:-) </small></small> </div>   --- class: title, smokescreen, shelf, no-footer # 仮想記憶<br>(Virtual Memory) 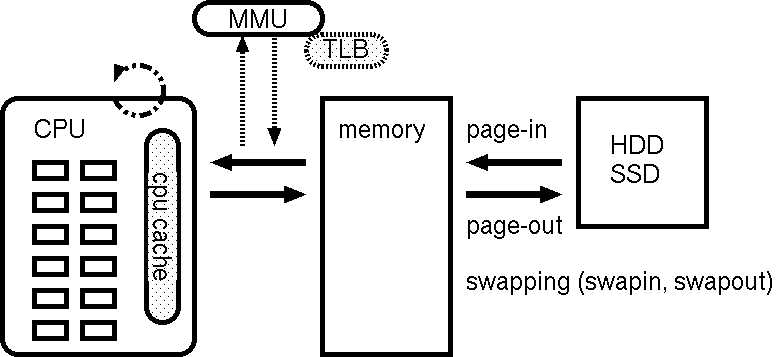 <div class=footnote> <small> </small> </div> --- class: compact # <small>メモリと仮想記憶システムの意義</small> <div class=footnote> <small><small> (脚注1) 基本情報の出題範囲には、ページング以外にセグメンテーションやオーバレイなどの手法も含まれます (脚注2) 逆に組み込み機器の場合、仮想記憶が不要なこともありえます (脚注3) 仮想記憶は 「<b>開発者の時間はコンピュータ(ハードウエア)より貴重</b>」 という思想を実現するものの一つと考えられます そもそも、 <B>ビジネス</B>目線の発想は 「<b>(納期によるけど)開発しなくてすむなら、それは大勝利</B>」 です。 プログラマが頑張って10%速くチューニングしても、 一年以内に出荷される次期Intel CPUが10%くらい速くなるので、 ハードウエアアップグレードのほうが確実です(ソフトのバグも増えない)。 なにしろ人件費が一番高いですからね! (脚注4) <b>なにかを開発する</b>ことが一番費用がかかる方法なので、それは最後の手段。 「DXがほげ〜」と叫ぶ人の大半が理解していないことがコレ </small></small> </div> - メモリ(main memory)つまり主記憶装置(ハードウエア)と、 仮想記憶(virtual memory)システムについて取り上げます - タイムシェアリングシステムのような複雑なOSでは**仮想記憶**は必須です - 1980年代以降のOSで主流の**ページング型仮想記憶システム**だけを解説します - 仮想記憶システムのおかげで、 システムの**物理的な詳細を気にせず**、 **一続きの大きなメモリを扱え**、 **プログラミングが楽**になります --- class: img-right,compact # <small>仮想記憶システムの要諦</small> <div class=footnote> <small><small> (脚注) 今回の白眉がコレ。 正確には<b>ページング型仮想記憶システム</b>の解説です </small></small> </div> 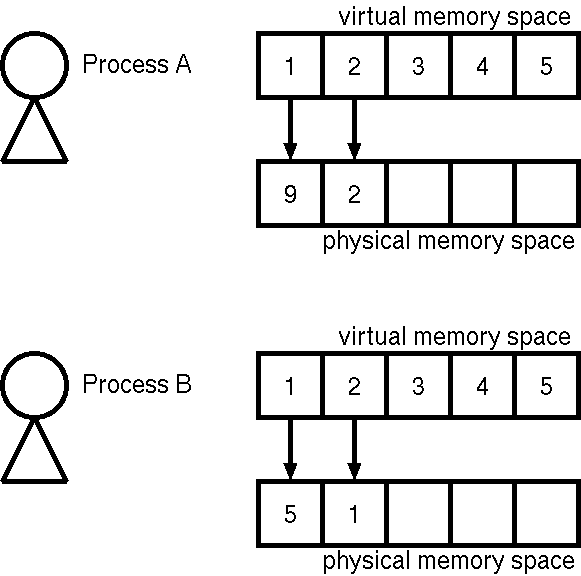 <small> - 右図の**箱(1〜9の数字)はメモリの概念図**です - **ページ**が処理単位(詳細は次頁以降) - プロセスAもBも仮想ページ1〜5(上側)を使っていますが、物理ページ(下側)は異なります。 各プロセスは同じ(仮想)メモリ空間(1〜5)を使っていると**錯覚**していますが、 実際に読み書きする物理メモリの場所は異なります - **物理的な詳細を気にせずプログラミングできるのは、この仕組みをOSが提供しているから**です </small> --- class: img-right,compact # <small>仮想記憶(Virtual Memory)とは?</small> <div class=footnote> <small><small> (脚注1) 仮想アドレス = virtual address (脚注2) MMU = Memory Management Unit (脚注3) かつて(70年代〜80年代あたりでは) 「(b)実際の物理メモリより大きなメモリ空間」に意味がありましたが、 現在の64ビット環境では逆の条件になってしまったので忘れてOK </small></small> </div>  <small> - プロセスに見せているのは**仮想アドレス**空間 - 仮想記憶システムを使うことで (a)**物理メモリの詳細を気にせず** (b)**実際の物理メモリより大きなメモリ空間**を扱えます - (a)によるメリット: **プロセスには仮想アドレス空間がリニア(直線的,一続き)**に見えます - 実装: CPUがメモリへアクセスする際、 (こっそり)**MMU**という回路が**仮想アドレスを物理アドレスへ自動変換**します。 通常MMUは**CPUに搭載**され、 **ページテーブル**(仮想->物理アドレス変換ルール表)の管理をカーネルが行います </small> --- class: img-right,compact # <small>仮想記憶のメリット、デメリット</small> <div class=footnote> <small><small> (脚注1) 物理メモリを直接あつかうMS-DOS上のプログラミングは大変です(googleしてみて:-) (脚注2) 大昔(70年代末〜20世紀の間?)はメモリ容量も小さかったため、 巨大な仮想メモリが使えることに意義がありましたが、 <B>物理メモリから溢れた分はHDD,SSDに置いてアクセスするため、ものすごく遅く</b>なります。 いまどき物理を越える仮想メモリが必要なプログラムを走らせたら負けで、 必要なメモリをお金で調達=解決するべきです </small></small> </div>  <small> - メリットは開発効率の向上です。 - (a)**メモリの詳細を気にせずにプログラムを書ける**ことが重要です - (b)物理メモリより大きな仮想アドレス空間が利用可能にもなりますが、 遅くなるので現在では重要視しません(脚注も参照) - デメリット - (a)実装が複雑になること - (b)ほぼMMUが必須であること - (c)アドレス変換オーバヘッド </small> --- class: img-right,compact # <small>ページング型仮想記憶システム</small> <div class=footnote> <small><small> (脚注) 実際にアクセスする場所は「アドレス = ページ番号x単位(4KBなど) + ページ内オフセット」です。 ページ番号だけを変換します </small></small> </div>  <small> - アドレス変換はバイト単位ではなくKB単位の固定長で行います。 この処理単位を**ページ**と呼び、大きさは4KBか8KBあたりが定番です - メモリをページで分割するタイプの仮想記憶が**ページング(paging)**型で、主流です - **ページテーブル**(アドレス変換ルール表)とは、仮想->物理ページ番号の変換表です。 表の要素(変換ルール)を**PTE**(Page Table Entry)と呼んでいます - HDD,SSDとメモリ間でスワップ(swap)します <small> - **ページイン** ... ストレージからメモリに読みこむ - **ページアウト** ... メモリからストレージに書き戻す </small> </small> --- class: img-right,compact # <small>アドレス変換の様子</small>  <small> - 各プロセスは同じ(仮想)メモリ空間を使っていると**錯覚**しています - 右図は、 <b>プロセスAもBも仮想ページ1〜5を使っています</b> が、 <b>実際に読み書きする物理ページは異なります</b> 。例: - プロセスAの仮想ページ1 -> 物理ページの9 - プロセスBの仮想ページ1 -> 物理ページの5 - (以下同様なので省略) - 物理メモリ上には複数のプロセスが共存します </small> --- class: img-right,compact # <small>ページング型仮想記憶システムのメリット、デメリット</small> <div class=footnote> <small><small> (脚注) 役割を考える方法も有り、 セキュリティ上よい実装が出来る可能性があります(詳細省略) </small></small> </div>  <small> - メリットは実装がシンプルなこと - 処理単位が固定長なため - メモリ空間を単純に固定長で分割し領域ごとの役割などは考えない - デメリット - MMUが必要(ソフト処理は非現実的) - 小さなメモリ領域が必要な場合でも、 ページ単位より小さな処理はないため非効率なことがある </small> --- class: compact # <small>ページ置換アルゴリズム</small> <div class=footnote> <small><small> (脚注1) これも基本情報処理試験の範囲なんですよね (脚注2) 余談ですが、ページ置換アルゴリズムを正しく実装するのは意外と大変で... なにしろPTEを参照する様子をだれかが見張っているの?(いえ見張って無いです:-) </small></small> </div> <small> - スワッピング(メモリとストレージ間でページを移動)しながら処理をしていますが、 メモリも大きくは無いため、 メモリに読みこもうとしても、すでにメモリに空きがないことがあります - 空きページを作る際は、 **ページ置換アルゴリズム**に従い、ページを削除(or ストレージへ書き戻し)後、 空いたページに必要なデータを読み込み(ページイン)します - ページ置換アルゴリズムの代表例 - **LRU (Least Recently Used)** ... もっとも長期間使われていないページを削除 - **LFU (Least Frequently Used)** ... もっとも参照回数が少ないページを削除 - **FIFO (First In First Out)** ... もっとも古いページを削除 </small> --- class: compact,img-right # <small>参照の局所性とTLB(PTEのキャッシュ)(1)</small> <div class=footnote> <small><small> (脚注) TLB = PTEキャッシュ相当ですがTLBという特別な名称があるので覚えてください </small></small> </div>  <small> - MMUはMMU自身が知らない(MMUのキャッシュにない)アドレス変換を要求された場合、 ページテーブルを検索し該当するPTEを読み込みます - カーネルがページテーブル(PTE)をメモリ上に準備しています - このテーブルサイズはかなり大きいので、メインメモリでないと置けません - 読み込んだPTEはMMUでキャッシュします - **同じPTEをしばらく使うことが多いのでキャッシュは有益**です - このキャッシュを**TLB**(Translation Lookaside Buffer)と呼びます </small> --- class: compact,img-right # <small>参照の局所性とTLB(PTEのキャッシュ)(2)</small> <div class=footnote> <small><small> (脚注) TLB = PTEキャッシュ相当ですがTLBという特別な名称があるので覚えてください </small></small> </div>  <small> - TLBのキャッシュヒットは仮想記憶の性能向上にとって重要ですが、 このキャッシュヒットの高さを期待できる理由が**参照の局所性(locality of reference)**です - プログラムには**参照の局所性**(経験則)があります - もっともわかりやすい例がループ(一部のメモリ領域だけを重点的に使う例)ですが、 プログラムには多かれ少なかれ参照の局所性があります <br> `for(i=0;i<N;i++){ sum+=i;}` </small> --- class: title, smokescreen, shelf, no-footer # <small>記憶装置(ハードウエア)の多段構造とキャッシュ</small> <div class=footnote> <small> </small> </div> --- class: img-right,compact # <small>コンピュータにおけるキャッシュの重要性</small> <div class=footnote> <small><small> (脚注) コンピュータネットワークでもキャッシュは重要です。 OSの速度にくらべてネットワークが遅すぎるため、 CDNなどのキャッシュサービスは通信の高速化に役立ちます </small></small> </div>  <small> - (初回にHDD,SSDから読み出す時は異なりますが)2回め以降、 読み書きは次のような多段構造 ``` CPU <- レジスタ <- CPU cache <- memory <- HDD,SSD CPU -> レジスタ -> CPU cache -> memory -> HDD,SSD ``` - 左側へいくほど高速・低容量 - CPU cacheも1次、2次、3次などと多段 </small> - **より高速なキャッシュから必要なデータを読みこめれば、 それだけ処理速度が上がります**(**キャッシュヒット**) - **デバイスごとの速度差が大きいため、キャッシュはコンピュータにとって重要** </small> --- class: img-right,compact # <small>記憶装置(ハードウエア)の多段構造(1)</small> <div class=footnote> <small><small> (脚注) 書類のなかには、滅多にアクセスしないけれど捨ててはいけないデータ(Cold data)があります。 そういったデータをHDDに置いています。 クラウド(AWS)も考慮に入れれば、 処理結果 -> SSD -> HDD -> AWS S3 -> AWS S3 Deep Archiveへと移動させていきます </small></small> </div>  <small> - プログラムやデータは、**安価で大容量ですが低速な補助記憶装置(HDD,SSD)**に格納していて、 使うときに始めて補助記憶装置から**主記憶装置**(メインメモリ)に読み込みます - CPUはメインメモリにあるデータを読みながら処理を進めますが、 メモリもCPUよりほぼ1桁低速なため、 一度読んだデータはCPU内の**キャッシュに格納し(遅い)メモリアクセスを減ら**します - キャッシュは**SRAM**、メインメモリは**DRAM**というLSIです。 <small> SRAMは高速・高価・低容量、 DRAMはSRAMにくらべ低速・安価・大容量。 使い分けが重要 </small> </small> --- class: img-right,compact # <small>記憶装置(ハードウエア)の多段構造(2)</small> <div class=footnote> <small><small> (脚注1) 書類のなかには、滅多にアクセスしないけれど捨ててはいけないデータ(Cold data)があります。 そういったデータをHDDに置いています。 クラウド(AWS)も考慮に入れれば、 処理結果 -> SSD -> HDD -> AWS S3 -> AWS S3 Deep Archiveへと移動させていきます <br> (脚注2) すでに磁気テープは日本(それも富士フィルムのみ?)でしか生産していません。 地味に世界中のクラウドを支えています </small></small> </div>  <small> - プログラムやデータは、 - 使うときに始めて補助記憶装置から**主記憶装置**(メインメモリ)に読み込みます - 補助記憶装置は通電していなくてもデータが消えない媒体です - 製品 - **安価で大容量ですが(CPUに比べれば)低速な補助記憶装置(HDD,SSD)**に格納しています - クラウドストレージも考慮に入れるべき時代 - 最強のバックアップメディアは**磁気テープ** </small> --- class: img-right,compact # <small>スワッピング(swapping)、スラッシング(slashing)</small> <div class=footnote> <small><small> (脚注1) そもそもスワップしたら負けなんですけどね;-) (脚注2) 本稿では4KBなどの固定長でswapする話をしますが、 16bit Unixではプロセス単位でswapするメモリ管理でした(swap-based system)。 どちらもswapという用語で紛らわしい (脚注3) HDDの処理単位(512B)がメモリの処理単位(4KB)と異なる場合もありえますが、 そういう差異はデバイス担当ソフトウエアなどで隠蔽します </small></small> </div>  <small> - メモリとHDD,SSD間の読み書きの単位は4KBなどの**固定長**、 この単位が**ページ**(復習) - データをストレージからメモリへ読みこみ、 (CPUで処理、メモリ上のデータを更新後)、 最終的に更新したデータをストレージへ書き戻すことも多いです。 このデータ交換が**スワッピング**です(復習) - あまりにも**スワッピング**が多いと、 ストレージへの(遅い)入出力に引きずられてOS全体のパフォーマンスが低下します。 この状態が**スラッシング**で、 これを避ける設計や運用が重要です </small> --- name: pause class: compact,col-2 # <small>(アーカイブ動画で見ている人も)一時停止して休憩</small> <div class=footnote> <small><small> 「30分ごとに雑談(休憩)をしろ」というのが指導教官の教え <br> 正確には「アメリカでは30分ごとにジョークを言わないといけない」だけれど、そんな洒落乙なこと無理:-) </small></small> </div>   --- class: title, smokescreen, shelf, no-footer # 割り込み <div class=footnote> <small><small> </small></small> </div> --- class: img-right,compact # <small>シリーズ構成、サーバの全体像との関係</small> <div class=footnote> <small><small> </small></small> </div>  <small> - シリーズ構成 - 第05回 - CPU - プロセス - メモリ(仮想記憶) - 割り込み - 第06回 - 競合状態と排他制御 - デバイスドライバ - ストレージ - 今回(第05回)の最後の1/3 - 図の(2)(7)(8)、 右側のデバイスドライバ(詳細は次回)のところもハードウエア割り込み </small> --- class: compact # <small>割り込み(interrupt)とは</small> <div class=footnote> <small><small> (脚注) 攻め=こちらから定期的に終わりましたか?と尋ねまくる方法もありますが、 それは効率がよくない </small></small> </div> <small> カーネルに気づいてほしいイベントがある時に、それを知らせる処理が**割り込み**です 1. カーネルに気づいてほしい時とは?例: - エラーが発生しました - 下請け(のデバイス)さんから「依頼された仕事の終了」を連絡したい - (一般ユーザプロセスが)カーネルさんにしかできない仕事を依頼したい 1. **特権権限**が必要な仕事 ... (一般プロセスに出来ない処理を)カーネルにしてもらいたい 1. 仕事が終わったか?を知る方法は2種類(**攻めvs受け**?)考えられます - 「処理が終わったら連絡して欲しい」という方法として**割り込み**を用います <br> (次回の「同期と排他制御」でも少し話します) </small> --- class: compact # <small>【復習】カーネルだけが特権処理を行います</small> <div class=footnote> <small><small> (脚注1) 演習ではsuもしくはsudoコマンドで管理者になって行う操作をしています。 そういった<B>演習/実務</B>で行うシステム管理(例:ユーザ作成,パスワード変更)も<B>OS管理者だけが行う特権処理</B>ですが、 ほぼ<B>設定ファイルの編集権限の制御(Unixセキュリティ,ユーザ権限)</B>の話なので、 今回のテーマとは毛色が異なります (脚注2) だれでもストレージに書きこめたら重要なデータを好きに書き換えできてしまいます。 各種入出力も同様で、入出力に介入できたら嘘の情報を入力、出力できます (脚注3) かつてのMS-DOS時代の(昔の)パソコンのように、 ユーザの区別が概念がない(個人向け)OSもありましたが、 現代では、個人向け製品でも、きちんと権限の概念を持つべきでしょう (もちろん家電製品なら不要ということはありえます。 炊飯器や冷蔵庫には要らなそうです:-) (脚注4) カーネルが関係ないのは、実行中の数値計算プログラムくらいか?(もちろん結果の入出力はカーネル) </small></small> </div> <small> - OSでは特権が必要な処理があります。典型例:**デバイスの操作** - そもそも、ほぼどんな処理も一般プロセスはカーネルにお願いしている形です - 例:プログラムの実行、ファイルシステムの操作/設定、ファイルの入出力 - **カーネルだけが特権処理を実行できる**ように実装するには、 **CPU**の**支援**が必要です </small> --- class: img-right,compact # <small>【復習】OSの階層セキュリティモデル</small> <div class=footnote> <small><small> (脚注) カーネルはスーパバイザ、システムコールはスーパバイザコールとも呼ばれます。 本稿ではUnixに合わせてカーネルとシステムコールという用語を使います。 仮想化で<B>ハイパーバイザ</B>という用語が出てきますが、 これはsuperより上位の動作なのでhyper:-) </small></small> </div>    <small> - 階層構造の**卵**もしくは**玉ねぎ**型モデル <small> - 真ん中(卵の黄身)は特権が必要とされるゾーン<br>(**カーネル**に相当する部分) - 境界線を通過できるのは特別な命令のみ - 卵の殻=**シェル** - 一般ユーザプロセスからカーネルへ依頼する仕組みが**システムコール**です - 殻の外はユーザアプリを動作させる世界 <br> (**ユーザランド**)、**特権処理は不可**です </small> </small> --- class: compact # <small>実行を一時中断するイベントは3種類</small> - CPUは機械語を読みながら処理を続けます。 特に何もなければ機械語を読みつづけ、実行しつづけます。 これが通常状態です - この通常処理を一時**中断**して**特別な処理に移るイベント**が**3種類**あります。 | 種類 | 別名 | 備考 | |------------------------ |---------------------- |------------------------------------------ | | システムコール | ソフトウエア割り込み | ユーザプロセスからカーネルへ依頼する方法 | | 例外 | | 0で割り算やハードウエアエラーなど | | デバイスからの割り込み | ハードウエア割り込み | ハードウエアの制御 | --- class: compact # <small>実行を一時中断するイベントの別分類(基本情報処理試験)</small> <div class=footnote> <small><small> (脚注1) 基本情報処理試験の分類では、こうなっています。 仕方ないので、この用語も覚えてください。 Unixカーネルのソースコードでは、こういう区別をした書き方をしていないので、 本稿では無視して前頁の用語のまますすめます:-) <br> (脚注2) 中分類は前頁とあわせていますが、 基本情報処理試験では、もっと細かい分類をした用語を覚える必要がある? </small></small> </div> - 割り込みは原因により二種類に大別できます。 <small> - 実行中のプログラムが原因でおこるものが**内部割込み** - プログラムに関係なくおこるものが**外部割込み** </small> | 大分類 | 中分類 | 概要 | |-------------- |---------------------- |------------------ | | 内部割り込み | エラー | ゼロで割ったなど | | | システムコール | ユーザプロセスからカーネルへ依頼する方法 | | 外部割り込み | エラー | ハードウエア障害 | | | ハードウエア割り込み | ハードウエアの制御 | --- class: img-right,compact # <small>システムコール: 特権処理をカーネルにおねがいする</small> <div class=footnote> <small><small> (脚注1) <B>コンテキスト切り替え(context switch)</B>は、 ユーザプロセスからカーネルプロセスへ切り替わる動作および逆の動作部分 <br> (脚注2) 3の処理が長い場合(例:HDD/SSDへの読み書き)、 途中で4へ進み、他のプロセスへswitchします。 3の処理終了(その合図が次頁)後のいつか、依頼主へ戻る4-5が行われますが、 その時期は3の処理とスケジューラ次第 (解説を適度な長さにするため不正確)。 </small></small> </div> 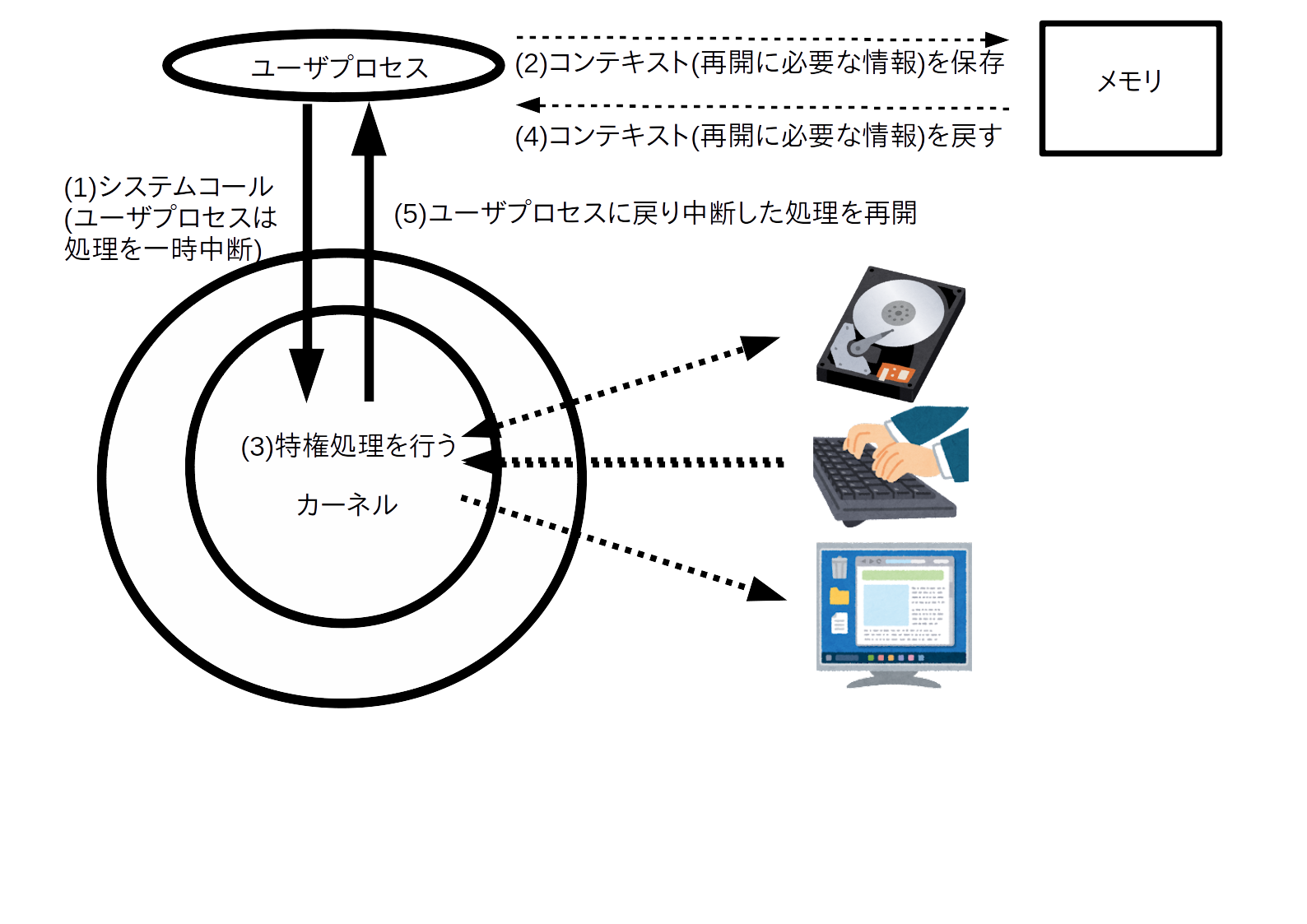 <small> 1. ユーザプロセスが**システムコール**を呼び出すと、CPUにより処理が一時中断されます 1. ユーザプロセスの情報(コンテキスト) をメモリに保存します 1. カーネルに制御が移り、カーネルが依頼された処理を行います 1. 保存していたユーザプロセスの情報を復元し、 中断されたところから再開できるように準備 1. ユーザプロセスに戻り、中断されたところから処理を再開します </small> --- class: img-right,compact # <small>ハードウエア割り込み: デバイスからの合図で処理を中断</small> <div class=footnote> <small><small> (脚注1) <b>処理のトリガーが異なるだけ>で、動作は前頁と同様です</b> (前頁はプロセスから自発的に依頼、本頁はハードウエアから合図) <br> (脚注2) 図ではユーザプロセスですが、 割り込まれるプロセスはカーネル(が実行中の処理)のこともあります <br> (脚注3) 前頁の脚注にもあるように、 適度な長さに抑えるために正確さは犠牲 (モヤモヤする人は是非ソースコードを読もう!) </small></small> </div> 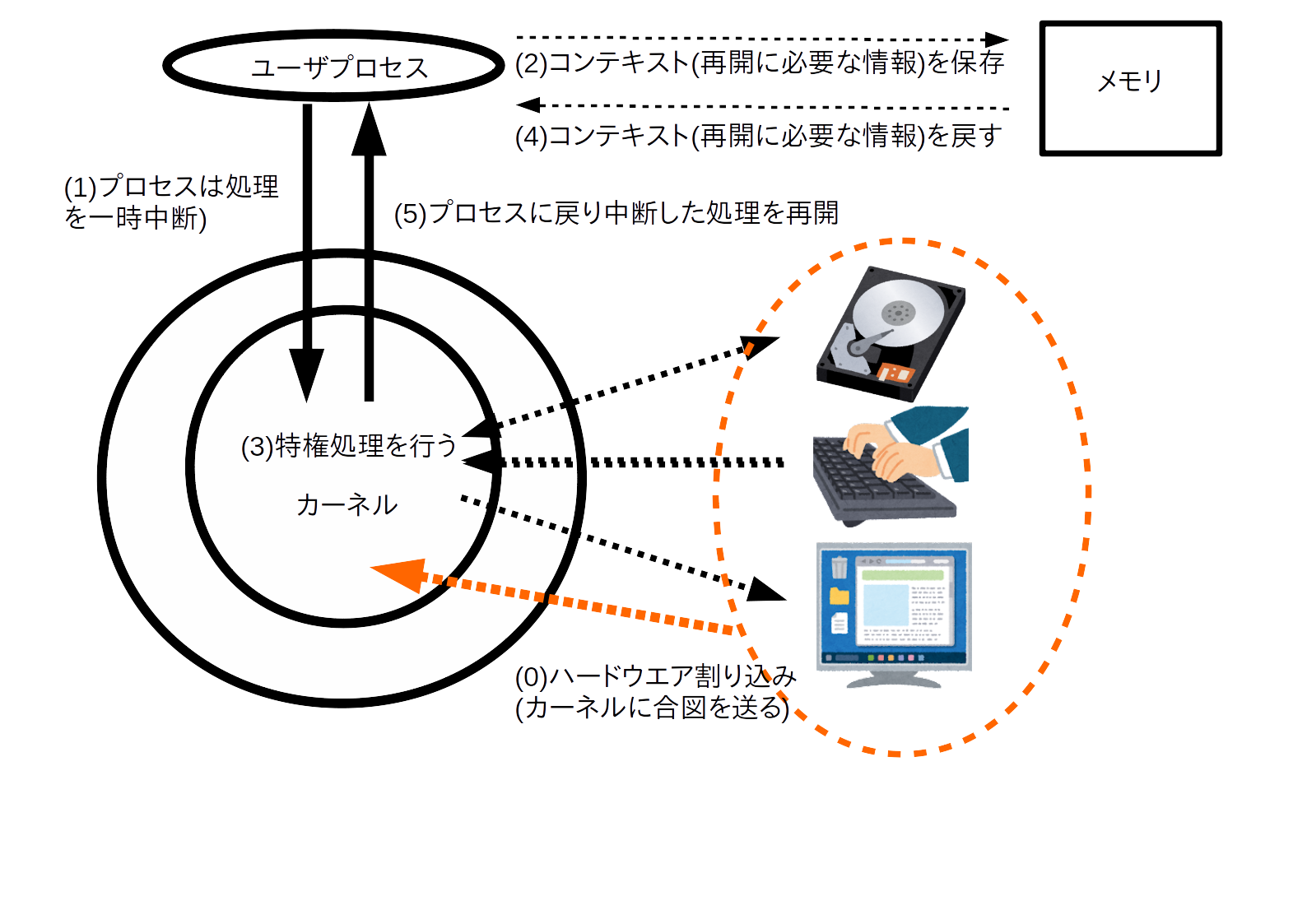 <small> ハードウエアから割り込み=終了の合図が送られてきます (右図の0;オレンジ色の部分) 1. CPUにより処理が一時中断されます 1. ユーザプロセスの情報(コンテキスト) をメモリに保存します 1. カーネルに制御が移り処理を行います **(例:HDD/SSDからの読み込み結果を返す準備)** 1. 保存していた情報を復元して中断されたところから再開できるように準備 1. ユーザプロセスに戻り、中断されたところから処理を再開します </small> --- class: img-right,compact # <small>エラー: デバイスからの合図で処理を中断</small> <div class=footnote> <small><small> (脚注1) 前半は前頁と同様ですが、後半は異なり、 プロセスを終了させることが多いです (ハードウエアからのエラーは致命的なレベルが普通なので処理を再開することは少ない)。 プロセスはzombieになり、後で死神=reaperが回収します:-)。 Unix Kernelではreaperという用語を使ってないですが、 他のソフトウエアではreaperという表現を使うことがよくあります (19世紀なかば以降の用例のようです) <br> (脚注2) 他の用例: CHAPTER 37: THE REAPER WHOSE NAME IS DEATH - L.M.Montgomery, Anne of Green Gables (1908) <br> (脚注3) この図は、実行中に0の割算などの致命的エラーがおきたケースです。 ハード障害などでは、そのハードを使おうとしたプロセスが終了するわけですが、 それは図で中断されたプロセスとは限りません (前頁までと同様、不正確です) </small></small> </div>  <small> エラーを知らせるために割込みをかけると 1. CPUにより現在実行中の処理が一時中断され 1. エラー情報とユーザプロセスの情報(コンテキスト) をメモリに保存します 1. カーネルに制御が移り、エラーに対応します。 たいていは致命的エラーなので該当するプロセスは終了です (死亡印をつけておきます) 1. プロセスに戻る途中でプロセスは終了 </small> --- class: img-right,compact # <small>割り込み優先度と多重割り込み</small> <div class=footnote> <small><small> (脚注1) 多重割り込みくらいまでは基本情報処理試験に出るから、やっておきますね... (脚注2) 突然プロセスAが中断し、 カーネルが処理Bを始めたとおもえば、割り込み処理がかかって処理Cに移り、 処理Cを終えると、プロセスEにコンテキストスイッチし ... (いつAに戻るんだ?) と言う具合にTSSは動いています。 これがソースコードを読みながらイメージできないとOSは理解できません </small></small> </div>  <small> - 割り込み処理の途中で、別の割り込み処理をすることもよくあります - 各割り込みに優先度を設定しています - 致命的なエラーは最高優先度で割り込むべき - 時計も優先度を高くしないと時間が狂います - 一方、ストレージやネットワークの読み書きはエラーや時計ほど優先されなくても大丈夫 - 右図は、 ストレージ(HDD)の処理をしている途中で、時計のハードウエア割り込みがかかり、 優先度の高い時計の処理を一時おこなったあと再びストレージの処理にもどっている様子です </small> --- name: register-details class: title, smokescreen, shelf, no-footer # <small>【参考】レジスタとアセンブリ言語の具体例</small> <div class=footnote> <small><small> (脚注) 【参考】部分は試験範囲外です </small></small> </div> --- class: compact # <small>【参考】レジスタ: PDP11 (16bit CPU)</small> | |レジスタ | 主用途 | 備考| | ---- | ---- | ---- | ---- | |汎用レジスタ| | | | ||r0 | 汎用 | | ||r1 | 汎用 | | ||r2 | 汎用 | | ||r3 | 汎用 | | ||r4 | 汎用 | | ||r5 | 環境ポインタ | Unixの慣例では環境ポインタ | ||r6 | スタックポインタ | spとも表記される | ||r7 | インストラクションポインタ | ipとも表記される | |メモリ管理レジスタ | SR0,SR1,SR2,SR3 | | SR1,SR3は機種依存 | |管理レジスタ|PSW | ステータスなど|PSW = Processor Status Word| --- class: compact # <small>【参考】レジスタ: Intel 8086 (16bit CPU)その1</small> ||レジスタ | 主用途 | 備考 | ---- | ---- | ---- | ---- | |汎用レジスタ | | | | ||AX | 計算用 | | ||BX | ポインタ | | ||CX | カウント | | ||DX | 一時記憶 | | ||SI | 転送元 | | ||DI | 転送先 | | ||BP | ベースポインタ | | ||SP | スタックポインタ | | ||IP | インストラクションポインタ | | |flags | ステータスなど | | | --- class: compact # <small>【参考】レジスタ: Intel 8086 (16bit CPU)その2</small> <div class=footnote> <small><small> (脚注) Intelって元々単なるメモリ屋さんだったからPCという思想に興味がなかったんでは? </small></small> </div> ||レジスタ | 主用途 | 備考 | ---- | ---- | ---- | ---- | |セグメンテーションレジスタ | | | ||CS | コード | ||DS | データ | ||ES | エキストラ | ||SS | スタック | <small> - Intel CPUは、もともとセグメンテーションという方式を使っていたため、 アドレス(ポインタ)はセグメントとセグメント内の位置(オフセット)をセットで指定します ``` セグメントアドレス:オフセットアドレス 30A4:0100 -> 30A40 + 0100 = 30B40 が実際のアドレス ``` - この方式は、 低機能なCPU上で低コストに大きなメモリを扱うには便利だったようです。 低コストとは「一度セグメントを決めればオフセットだけで処理可能=アドレス用のメモリも小さくてOK」だから </small> --- class: compact # <small>【参考】Intel CPUでループ(C言語)</small> <small> ``` #include <stdio.h> int main (int argc, char **argv) { int i, sum; sum = 0; for (i = 0; i < 10; i++) { sum += i; } printf("sum = %d\n", sum); } ``` - 単純な足し算をするループです。コンパイルするとCPUが理解できる**機械語**になります - 次頁では、 このループ本体部分の機械語を**アセンブリ言語に逆変換**(disassemble)したものと、 その各行の解説をしています( CPUはIntelです。 本当は64bit環境なので少し違うのですが、 前頁にあわせて、アセンブリ言語と解説は16bit風になっています) </small> --- name: disassembled-loop class: compact # <small>【参考】Intel CPUでループ(main部分のアセンブリ言語)</small> ``` objdumpしてmain部分を抜粋(+最初の数行と最後の2行を省略して一頁に)したもの 注: -0x8(%bp)は省略記法,C言語風に書けば「bpポインタに対して *(bp-8) 」相当;mov命令はmoveですが実質コピーです 機械語 アセンブリ言語 解説 c7 45 f8 00 00 00 00 mov $0x0,-0x8(%bp) -0x8(%bp)を0に初期化(変数sumとして利用) c7 45 fc 00 00 00 00 mov $0x0,-0x4(%bp) -0x4(%bp)を0に初期化(変数iとして利用) eb 0a jmp 4行後のアドレス forループの条件部分へジャンプ(4行先のcmp行) 8b 45 fc mov -0x4(%bp),%ax axレジスタに変数iを代入 01 45 f8 add %ax,-0x8(%bp) axレジスタの値を変数sumに加算(sum+=i相当) 83 45 fc 01 add $0x1,-0x4(%bp) 変数iに1を加算(i++相当) 83 7d fc 09 cmp $0x9,-0x4(%bp) 比較 i<=9 をし、結果をフラグレジスタに保存 7e f0 jle 4行前のアドレス フラグレジスタを見て結果がtrueなら4行前へ戻る(ループ) 8b 45 f8 mov -0x8(%bp),%ax 変数sumの値をaxレジスタへコピー 89 c6 mov %ax,%si siレジスタにaxレジスタの値をコピー(変数sum) bf ce 09 40 00 mov $0x4009ce,%di diレジスタにformat文の文字列アドレスをコピー b8 00 00 00 00 mov $0x0,%ax axレジスタを0に設定 e8 a3 fb ff ff call printfのアドレス printf関数(引数はdi,siに設定済)を呼び出す b8 00 00 00 00 mov $0x0,%ax axレジスタを0に設定(関数の返り値の設定) ``` --- class: title, smokescreen, shelf, no-footer # <small>【参考】割り込みとメモリレイアウト</small> <div class=footnote> <small><small> メモリレイアウト例と割り込みの関係を解説 </small></small> </div> --- class: img-right,compact # <small>【参考】メモリ最下部にある割り込み設定の例</small>  <small> - DEC PDP11上のUnix第6版(16ビットCPU)における割り込み設定の例です。 縦はアドレスの番地(8進数)です。 横幅は32ビットで、16ビットの設定を2つ並べて書いています。 - メモリの一番下に、 アドレス0番地から上に向かい、 割り込みベクタの定義が並んでいます。 - たとえば時計(水晶振動子)からのハードウエア割り込みの場合、 アドレスの64番地から設定を読み込むようにハードウエアを作りこみます。 読み込むのは「時計の関数アドレス」と「優先度6」という設定で、 これらをCPUに設定します(そのような動作を自動的にするようCPUが作られています) </small> --- name: computer-basic class: title, smokescreen, shelf, no-footer # <small>【参考】割り込みベクタの例</small> <div class=footnote> <small><small> </small></small> </div> --- class: compact # <small>【参考】PDP11 割り込みベクタ</small> |ベクタ位置 | 周辺デバイス | 割り込み優先度 | プロセス優先度 |-------|-----------------------|---------------|---------- |060 | テレタイプ入力 | 4 | 4 |064 | テレタイプ出力 | 4 | 4 |070 | 紙テープ出力 | 4 | 4 |074 | 紙テープ出力 | 4 | 4 |100 | クロック(電源周波数) | 6 | 6 |104 | クロック(プログラマブル) | 6 | 6 |200 | ラインプリンタ | 4 | 4 |220 | RKディクドライブ | 5 | 5 --- class: compact # <small>【参考】PDP11 トラップベクタの例</small> |ベクタ位置 | トラップ種別 | プロセス優先度 |-------|-----------------------|------------ |004 | バスタイムアウト | 7 |010 | 不正命令 | 7 |014 | bpt トレース | 7 |020 | iot | 7 |024 | 電源異常 | 7 |030 | エミュレータトラップ命令 | 7 |034 | トラップ命令 | 7 |... | ... | ... |114 | 11/70 パリティ | 7 |240 | プログラムされた割込み | 7 |244 | 浮動小数点エラー | 7 |250 | セグメンテーション違反 | 7 --- # <small>【参考】Intel 8086 割り込みベクタ</small> |周辺デバイス | 割り込み番号 |------------------------|--------------- |タイマー | 0x08 |キーボード | 0x09 |RS-232C | 0x0B |RS-232C | 0x0C |フロッピーディスク | 0x0E --- class: compact # <small>【参考】NEC PC-9800 割り込み番号の例</small> |周辺デバイス | 割り込み番号 |------------------------|--------------- |タイマー | 0x08 |キーボード | 0x09 |CRTC | 0x0A |RS-232C | 0x0C |フロッピーディスク | 0x13 --- class: img-right,compact # <small>【参考】8086 リアルモードにおける割り込み(キーボードの例)</small>  <small> - 割り込みベクタはメモリ空間の先頭1024バイトに書かれており、 タイプひとつごとに4 バイト(2 バイトの offset と 2 バイトの CS)を使用。 よってロードするベクタは「4*(タイプ-1)」の位置 1. 割り込みタイプ09Hがかかる 1. CS,IP,flags をスタックへ退避 1. 0024Hからタイプ09Hの割り込みベクタをロードする 1. ロードしたCS IPを実行する <br> (キーボードの関数を呼び出して処理) 1. スタックへ退避しておいたCS,IP,flagsを元に戻す </small>